多轮对话陷阱:为什么最强LLM依然会在交流中迷失方向

这篇论文《LLMs Get Lost In Multi-Turn Conversation》主要探讨了大型语言模型(LLMs)在多轮对话中处理用户需求时表现出的显著性能下降现象,即“迷失在对话中”(Lost in Conversation)。具体来说,论文的主要内容包括以下几个方面:
1. 研究动机与问题背景
当今的LLMs通常作为对话接口使用,理想情况下,应该能够帮助用户在多轮交互中逐步明确和细化需求。然而,目前的评估多集中在单轮、完全指定的任务设置,而现实对话中用户经常给出不完整或欠规格(underspecified)的指令,需要多轮沟通才能明确需求。论文指出,这种欠规格是实际应用中十分普遍的情况,但相应的多轮对话能力却没有得到充分评估和理解。
为了模拟多轮欠规格对话场景,作者设计了一个“分片”方法:将完整的指令拆成多个较小的信息“碎片”(shards),每轮对话只暴露一个碎片,从而模拟真实中用户逐步完整表达需求的过程。基于分片的指令,构建了自动化模拟用户和助手对话的系统,在此环境中对15个不同大型语言模型进行了超过20万次的对话模拟实验。
3. 核心实验发现——多轮对话中性能显著下降
- 性能下降幅度大:模型在多轮(sharded)欠规格对话中的平均表现比单轮完整指令状态下降了39%,即使是两轮对话也会造成-明显下降。
- 主要原因是可靠性(unreliability)下降,而非能力(aptitude)下降:分析显示模型的固有能力并没有大幅退化,但多轮对话中表现起伏极大,同一任务多次模拟表现差异剧烈。
- 模型容易“迷失”:因提前做出假设,过早给出完整答案,依赖先前错误的回答,导致产生冗长且错误的答案,难以根据后续用户信息进行有效修正。
4. 多轮对话性能下降的具体机制分析
- 过早尝试回答:模型在用户还没有提供足够信息时,就迫不及待尝试给出完整解答,容易陷入错误。
- 回答冗长膨胀(answer bloat):更多轮次的对话中,回答会越来越长且肥大,包含大量假设和错误信息。
- “遗忘中间轮”现象:模型更关注对话开头和末尾的信息,中间轮的内容容易被忽视或遗忘。
- 过度冗余回复:模型生成的每轮回答过于详尽,反而干扰后续理解,降低整体对话质量。
论文地址:https://arxiv.org/pdf/2505.06120
dataset:https://huggingface.co/datasets/microsoft/lost_in_conversation
下面来具体进行论文解析:
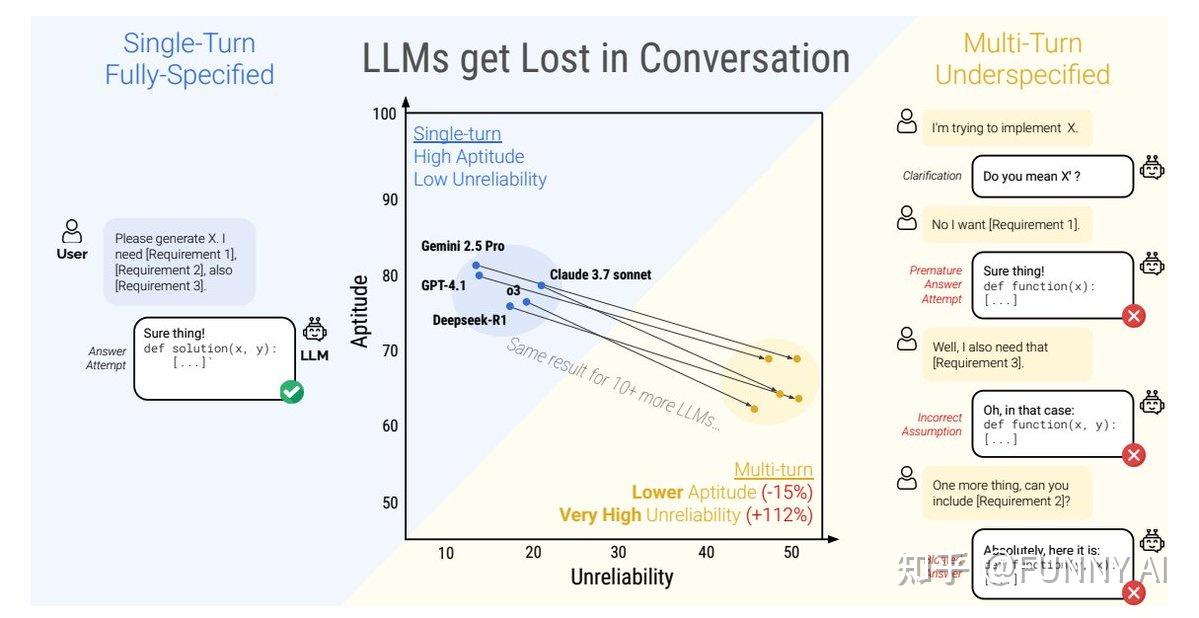
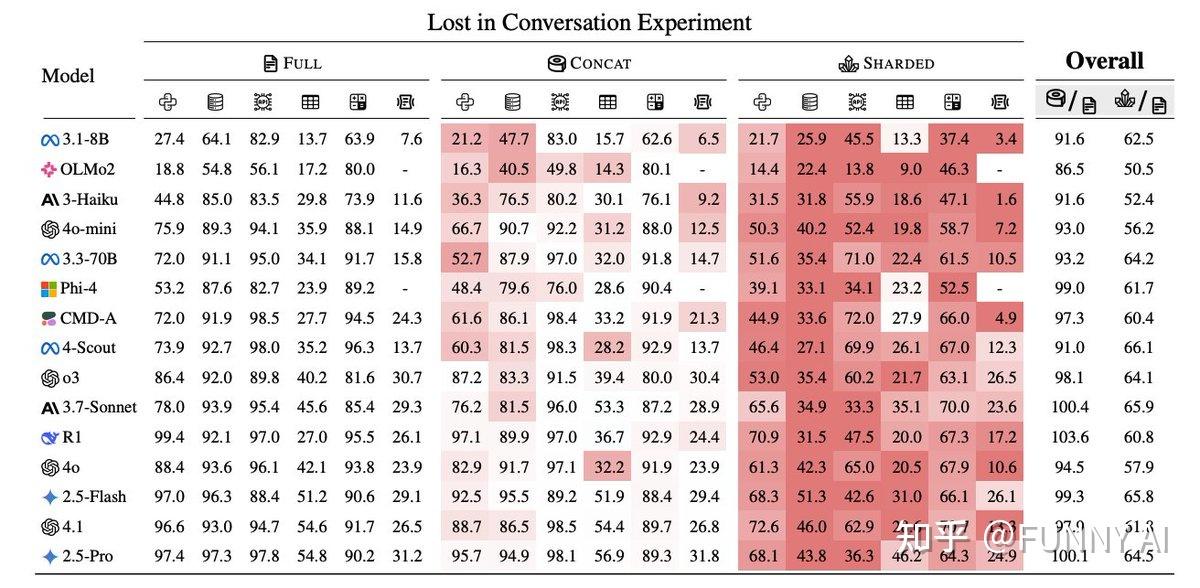
作者对 15 个顶级 LLM(包括 GPT-4.1、Gemini 2.5 Pro、Claude 3.7 Sonnet、Deepseek-R1 等)进行了大规模模拟,涉及六个生成任务(代码、数学、SQL、API 调用、数据到文本和文档摘要)。

多轮对话设置下性能严重下降,所有测试的 LLM 在多轮对话(未指定指令)下的性能均显著低于单轮对话(完全指定指令)。
即使是 SoTA 模型,在六项任务中的平均性能下降也高达 39%。例如,在单轮对话中准确率 > 90% 的模型,在多轮对话中准确率通常会下降到约 60%。
性能下降源于不可靠性,而不仅仅是能力。 性能损失分解为最佳情况下能力的适度下降(能力下降,-15%)和不可靠性的急剧上升(+112%)。 在多轮对话中,最佳响应和最差响应之间的差距显著扩大,这意味着LLM 的一致性和可预测性大大降低。 单轮对话中性能优异的模型与多轮对话中性能较弱的模型一样不可靠。切勿忽视多轮对话中的测试和评估。
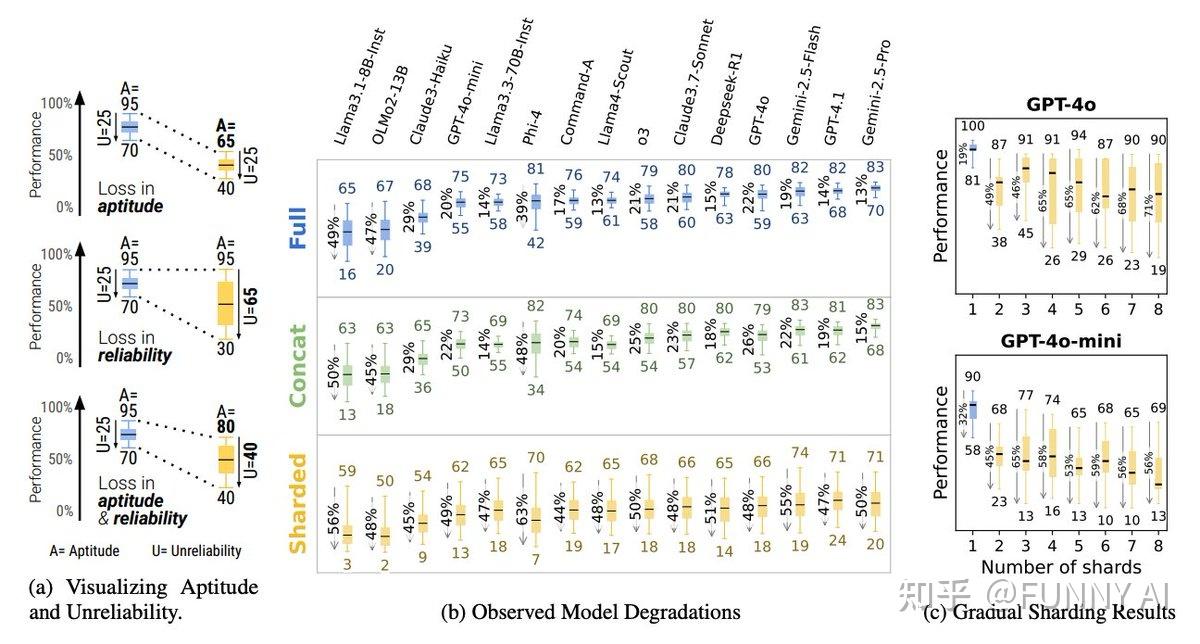
LLM“迷失”的主要原因
- 在对话初期做出不成熟的、往往是错误的假设。
- 在掌握所有必要信息之前就尝试给出完整的解决方案,导致答案“臃肿”或偏离主题。
- 过度依赖之前的(可能不正确的)答案,随着对话的进展,错误会不断累积。
- 输出内容过于冗长,这会进一步混淆上下文,并使后续对话更加混乱。
- 过度关注第一轮和最后一轮,而忽略了中间轮次揭示的信息(“中间迷失”效应)。

任务和模型无关
这种效果在模型大小、提供者和任务类型方面都表现出色(除了像翻译这样真正具有情景性的任务,因为多轮推理不会引入歧义)。 即使是额外的测试时推理(例如 o3、Deepseek-R1 等“推理模型”)也无法缓解性能下降。
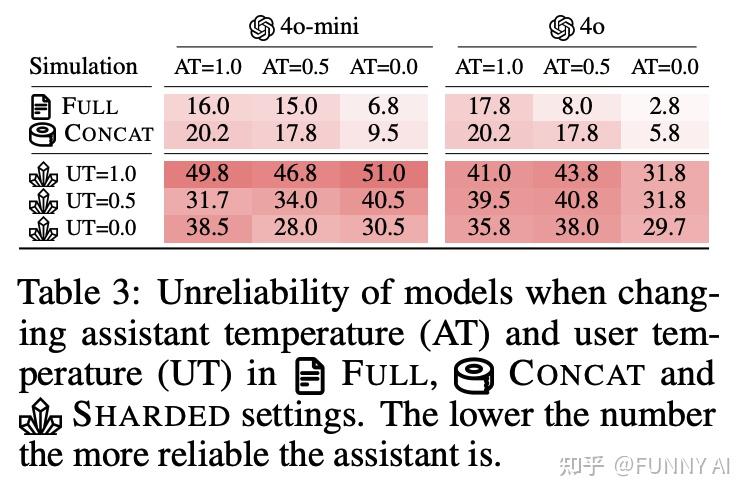
代理和系统级修复仅部分有效
重演和“滚雪球”策略(系统在每一轮中重复所有先前的用户指令)部分缓解了性能下降,但无法完全恢复单轮可靠性。 降低生成随机性(温度)的效果也有限;即使在 T=0 时,不可靠性仍然存在。良好的上下文管理和内存解决方案在此发挥着重要作用。
对不同应用方的启示
- 系统开发者:建议不仅优化单轮能力,更要重视多轮对话中的可靠性,模型应具备更好地整合多轮信息、适时发起澄清、避免过早假设的能力。
- 模型构建者:呼吁在训练和评估中增加对多轮欠规格对话能力的关注,研发更具鲁棒性和可靠性的对话模型。
- NLP研究者:推荐构建多轮欠规格对话数据和基准,推动多轮任务与单轮任务能力的统一评估。
终端用户:提醒用户尽量在单个指令中集中准确表达需求,或多用重启新对话的策略,避免持续局部纠正导致模型表现退化。
论文的局限性与未来方向
实验项基于全自动模拟用户,缺乏真实人类多轮交互的复杂性,实际多轮对话中的“迷失”现象可能更严重。 任务种类聚焦于分析型、结构化生成,未覆盖创意写作等开放型任务。 仅验证了英语文本任务,尚未探索跨语言或多模态情况下模型的多轮表现。
总结来说,这篇论文揭示了当前主流大型语言模型在多轮欠规格对话中的“迷失”问题:即使在表现优异的单轮任务中,模型在现实中常见的多轮未完全指定场景下,稳定性和性能都大幅下降,呼吁构建更具多轮交互可靠性的语言模型,推动评估和训练向真实人机多轮对话场景靠近。