

核心观点总结
本次访谈的核心观点围绕着人工智能,特别是大型语言模型在推理能力上的未来发展方向。主讲人Dan Roberts强调,OpenAI的战略重心正在从传统的预训练计算转向强化学习(RL)和“测试时计算”(test-time compute)。他认为,未来的AI模型将通过在测试阶段投入更多时间进行“思考”和推理来提升性能,这代表了AI扩展的一个全新维度。OpenAI的目标是让模型能够做出类似爱因斯坦发现广义相对论那样的重大科学贡献,而实现这一目标的关键在于大规模扩展强化学习的应用,甚至使其在计算资源中的占比远超预训练,彻底颠覆当前“预训练是蛋糕,强化学习是樱桃”的普遍认知。为此,OpenAI正致力于大规模投资计算基础设施,并同步发展“扩展科学”(scaling science),以理解和预测这些更强大模型的行为。
引言:Dan Roberts 与推理的重要性
大家好,Dan Roberts,前红杉资本团队成员,多年来一直向我们传播关于推理的理念,尤其是在过去的两到三年半时间里。我们曾共事大约一年到一年半,我从Dan身上学到了很多。我非常激动他能在这里更广泛地分享他的见解。
我想分享一个小插曲:去年的AI Ascent大会上,他正准备离开红杉加入OpenAI。他当时对此事严格保密,毕竟这是相当重要的信息。当时Alfred和Sam在台上谈话,Alfred突然说:“哦,顺便一提,Dan要去OpenAI了。”我看到Dan的脸,他当时一定非常尴尬。很高兴你现在已经度过了那个阶段,并能和我们分享一些关于推理的思考。
O1模型:测试时计算能力的突破
嗯,你似乎用了我准备的开场白,那我就直接进入正题了。
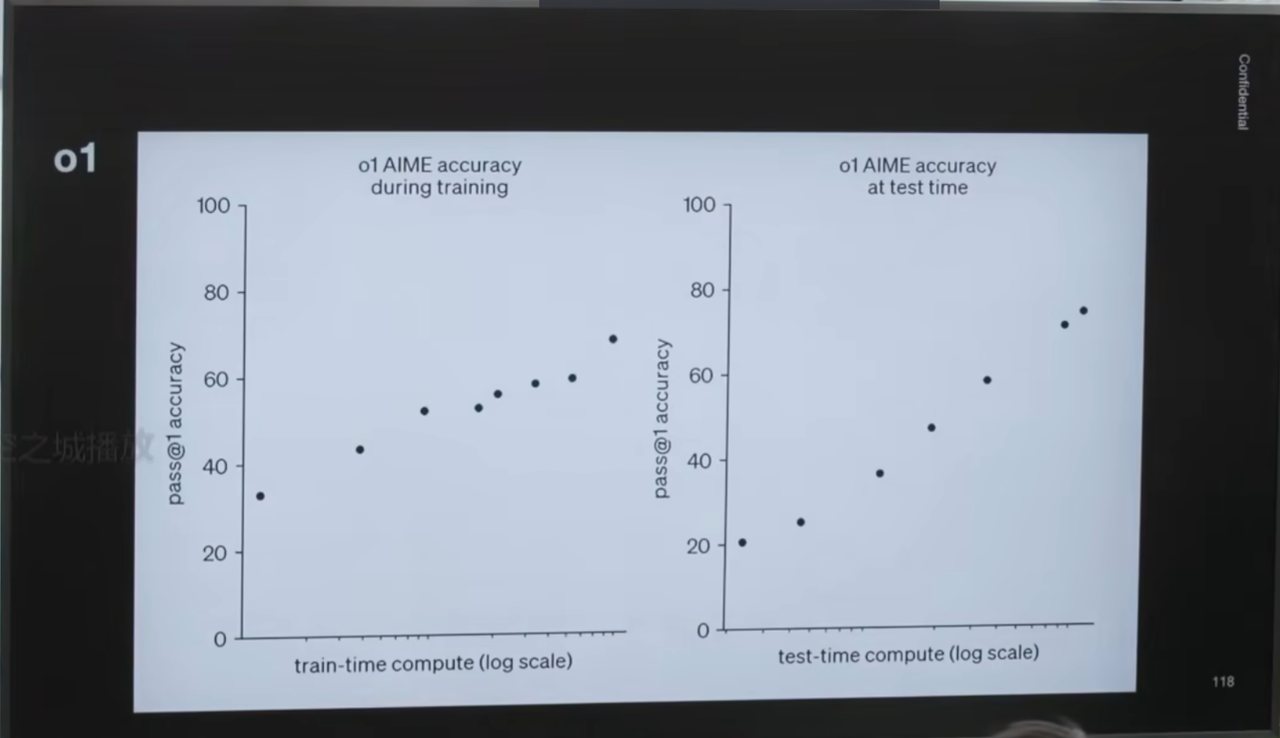
相信很多人知道,去年九月,OpenAI发布了一个名为O1的模型。这张图来自我们的博客文章,请注意,Y轴代表模型在某种数学推理基准上的性能,而X轴则更有意思。左边的图表显示,模型的性能随着训练时间的增加而提升——这是所有训练AI模型的人都熟悉的现象。真正令人兴奋的是右边的图表,它表明模型的性能同样随着“测试时计算”(test-time compute)的增加而提升。我们教会了它推理,它会花时间思考,思考的时间越长,性能就越好。顺便说一句,这里真热。这个发现非常重要,我们甚至把它印在了T恤上。这是一个全新的扩展维度,不仅仅关乎训练,也关乎测试阶段。

思想实验:从量子电动力学到爱因斯坦
那么,这意味着什么呢?我们有了一个会思考的模型,让我们来做一个思想实验。
上个月,我们发布了O3,一个推理能力更强的模型。我的背景是物理学,所以你可以用物理问题来考它。这是一个关于量子电动力学的问题。你可以看到,有人在一张纸上提出了一个问题。你可能见过这类模型在测试时的表现:它能够思考,能够迭代,能够深入钻研。纸上有一个费曼图,这是一种表示这些计算的方法。模型会进一步思考,然后开始解答问题,并最终给出了正确答案。整个过程大约花了一分钟。顺便提一下,在发布这篇博客文章之前,一位同事让我检查这个计算。我花了大约三个小时,尽管这个计算方法在我拥有的四本教科书中都有提及,但我需要追踪它的每一步,确保所有正负号都正确,并验证我得到了正确的答案。
我们现在的模型能在一分钟左右完成一些相当复杂的计算。但我们的目标是什么呢?
让我们再做一个思想实验,一个关于爱因斯坦的思想实验。想象我们回到1907年,那时他还没有开始研究广义相对论。我们问他一个广义相对论期末考试级别的问题(这个问题实际上是GPT-4.5编的,但我可以确认这是一个合理的问题类型)。我们是OpenAI,所以我们会用“爱因斯坦v1907-super-high x”这样的版本来提问,以确保获得最强的推理能力和最大的努力。爱因斯坦,我猜他是个视觉型思考者,会想到电梯和自由落体——这些是学习广义相对论时会接触到的概念。他会进行一些计算,思考橡胶板和小球的模型。看起来他中途被量子力学分心了一下,我们的模型有时也会分心。好了,这看起来开始接近黑洞了。我也不知道为什么他在所有这些场景里都会想到自己。就是这个,我想要的黑洞和虫洞,这是正确答案。事实证明,GPT-4.5无法得出这个正确答案,我们需要O3,O3成功了。我觉得我在OpenAI的角色主要就是检查物理计算,而不是做AI研究。

关键在于,模型得到了正确答案。爱因斯坦也会得到正确答案,但他大概需要八年时间来解决这个问题。或者说,他会用八年时间发现广义相对论,就像历史上发生的那样,然后就能回答这个问题了。我们现在的模型思考一分钟,可以重现教科书上的计算及其微小改动。但我们希望它们能为人类知识和科学做出重大贡献。
核心战略:强化学习与计算规模的扩展
回到这张图,我们如何实现这个目标呢?现在让我们关注左边的图表:模型的性能随着训练量的增加而提升。我们进行的训练主要是强化学习(RL)。
所以,我今天想传达的主要信息是,我们要大规模扩展强化学习。一年前,我们发布了GPT-4.0,它所用的计算资源全部是预训练计算。你可以想象,之后我们开始做一些导致“测试时计算”能力提升的事情,所以我们为O1模型增加了一些强化学习计算。需要说明的是,这只是一个示意图,但方向上是正确的。O3模型可能拥有更多的强化学习计算。在未来的某个时刻,我们可能会有大量的强化学习计算。而在更遥远的未来,或许强化学习计算将完全占据主导地位。

“蛋糕与樱桃”的颠覆:强化学习的主导地位
我认为这是一个有点反主流的观点,但这确实是我们的方向。为了强调这种反主流的特性,请看这张幻灯片。有些关注AI研究的人可能认得,这是几年前(根据版权信息看是2019年)杨立昆(Jan LeCun)制作的。我显然是借用了这张图。这是一张可能难以理解的复杂幻灯片,但幸运的是,我们有模型可以为我们总结。
核心观点是:预训练就像一个巨大的蛋糕,而强化学习则被认为是蛋糕上的一颗小樱桃。这基本上就是之前那张图所展示的——颜色搭配纯属巧合,但我认为效果很好。而我们的目标是彻底颠覆这个比喻:我们或许拥有同样大小的蛋糕,但我们想用一颗巨大的强化学习“樱桃”将其彻底覆盖。
OpenAI的宏伟蓝图与挑战
那么,我们的计划是什么?
我不能告诉你们具体的计划。我把幻灯片发过去后,公关部门似乎把所有内容都涂黑了。实际上,我当时还有点担心他们会把这张“涂黑”的幻灯片也给涂黑了,但幸运的是,我联系的Brianna人很好,所以一切顺利。
事实上,你们知道我们的计划,我想我们已经说得很清楚了:我们正在扩展计算能力。这意味着什么?我们将筹集5000亿美元,在德州的阿比林购买土地,建造一些建筑,在里面放置计算机。今天在座的一些人,我们早些时候聊过,也许会帮助我们实现这个目标。然后,我们将训练一些模型,希望能从中获得大量收入,然后再建造更多的建筑,放置更多的计算机,以此类推。
我们正在扩展我们的计算能力。与此同时,我们还希望发展“扩展科学”(scaling science)。这是我在OpenAI所做的工作之一,也是我思考的问题之一。这张图来自我们GPT-4的博客文章,它早于我加入的时间,但我认为它非常鼓舞人心且令人印象深刻。左下角的这个点是GPT-4最终的损失性能。这些点是他们在此过程中进行的一些实验,这是对数坐标,所以它们的规模要小得多。而这条虚线是预测线。所以,他们精准地预测了结果。他们着手训练这个比以往任何模型都要大的模型,并且确切地知道它会达到什么样的性能。
现在,我们有了“测试时计算”和强化学习训练这些新的方向,我们必须抛弃一切,重新定义扩展计算能力的意义。我们正在扩展,我们需要扩展科学,因为我们希望成为扩展科学的引领者。
有一个观点,播客主持人Dwarkesh Patel曾告诉我,我们现在的模型感觉有点像“白痴天才”(idiot savants),它们还没有发现广义相对论。我不知道这是为什么。
可能是因为我们问的问题不对。在研究中,很多时候你提问的方式比过程和答案更重要。所以我们需要确保问题提得正确。另一个可能的问题是,我们可能在太多竞赛数学问题上进行了训练,导致我们的模型在不同方面的能力参差不齐。我猜在这些情况下,你可能会得到一些整数结果,感觉有点不尽如人意。但我认为真正会发生的是,我们需要进一步扩大规模,当我们做到这一点时,结果将会非常惊人。
结语:九年后,AI发现广义相对论?
最后,关于未来展望。我去年也在这里,很高兴能再次来到这里。这其实很简单,因为我想Constantine之前也展示过这张图,他展示的是Y轴非半对数版本的图。这张图显示了AI智能体能够完成的任务长度呈指数级增长,大约每七个月翻一番。根据这张图,它们现在大约能完成一小时左右的任务。那么明年,我们会达到什么水平呢?大约是两个半小时到三个小时之间。
在AI领域做预测是很危险的,每个人总是会错。但我或许可以试着外推一下这条线。我们之前谈到爱因斯坦花了八年时间思考。那么,从现在开始,要达到八年的思考能力,我们需要大约16个倍增周期。这意味着,我想说的是,九年后,我们将拥有一个能够发现广义相对论的模型。
谢谢大家。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...