

核心观点总结
-
Deep Research的核心能力:高效的深度研究与分析。 Deep Research 并非简单的信息检索工具,它具备在5到30分钟内浏览海量在线资源、进行深度推理,并生成媲美专业研究分析师水平的、引用全面的详尽报告。这种能力使其能在短时间内完成传统人工需要数小时甚至更久才能完成的复杂研究任务,极大地提升了信息获取和分析的效率。它通过专门微调的O3模型版本,实现了在网页浏览和数据分析方面的优化。
-
Deep Research的研发初衷与实现路径:源于真实需求,通过强化学习与工具赋能打造。 OpenAI启动Deep Research项目的初衷,是希望模型能直接学习和执行用户日常生活及工作中的实际任务,而在线浏览因其普遍性和相对可控性成为了理想的起点。其开发过程并非一蹴而就,而是首先通过快速原型激发内部兴趣,随后通过创建专门的强化学习任务,教会模型掌握浏览、数据分析等关键技能,并为其配备了浏览器访问、代码执行(用于数据分析和图表绘制)等必要工具,最终使其具备了强大的自主研究能力。
-
Deep Research的未来展望:从信息整合迈向实际行动,并持续提升可靠性。 尽管Deep Research目前仍存在偶尔“犯错”(如产生幻觉)的可能,但OpenAI对其未来发展规划清晰。除了持续提升模型的可靠性、将其能力整合到如O3等核心推理模型中,以及引入企业内部知识库等私有数据源外,一个更具突破性的目标是让Deep Research超越当前的信息整合与报告生成,进化到能够自主“采取行动”的阶段。这意味着AI将不仅仅是信息助手,更有可能成为能够直接执行任务的智能代理。
嘉宾介绍与开场
非常激动地欢迎Esa FullFord,她创造了一款我们都熟知、使用且热爱的产品——OpenAI的Deep Research。她将为我们介绍这款产品,分享研发历程、未来方向,并进行现场演示。她为了这次活动特地从韩国赶来,今天凌晨四点四十五分才刚刚落地。请大家以最热烈的掌声欢迎Esa来到红杉资本!
Deep Research:不仅仅是搜索
谢谢。大家好,我是Esa,OpenAI Deep Research团队的负责人。有些人可能知道,Deep Research 是一种由EPC负责的代理能力,它能在线进行多方面研究,以解决非常复杂的任务。用户给出一个指令,Deep Research会花费5到30分钟浏览大量在线网络资源,对找到的内容进行推理,然后生成一份引用全面、内容详尽的报告,水平接近于专业研究分析师。它能在几分钟内完成人类需要数小时才能完成的工作。Deep Research由一个我们专门为优化网页浏览和数据分析而微调的O3模型版本提供支持。稍后我会详细介绍我们是如何做到的。

缘起:为何构建 Deep Research?
首先,谈谈我们最初构建Deep Research的一些背景。大约一年多前,我们观察到公司内部在强化学习和推理模型方面取得了显著进展。当时我们的训练主要集中在数学、科学和编程任务上。我们发现,这类任务的训练能在一定程度上泛化到其他领域。但我们好奇,如果直接针对用户日常生活中的任务进行训练,会产生怎样的效果?我们能否通过直接针对这些场景进行训练,从而打造出一个真正实用的模型?
我们认为,在线浏览是一个非常好的切入点。因为许多人在各种领域和工作中,乃至日常生活中,都会进行在线浏览。此外,在线浏览也是一个理想的“沙盒环境”,考虑到安全因素,它相对更为可控,是启动代理(agents)研究的一个良好开端,暂时无需引入完整的代理功能。
为了实现这一目标,我们首先需要激发大家的兴趣。我和今天也在场的Thomas Simpson团队的Yash Patil一起,通过简单的模型指令(prompting)快速搭建了一个演示版本,展示了Deep Research产品可能的样子。我们当时并没有训练任何特定的模型,只是为了点燃大家的热情。随后,我们才正式启动了针对Deep Research的模型训练流程。
这个过程包括创建强化学习任务,用以教会模型我们期望它掌握的浏览能力和数据分析能力。同时,我们还开发了相应的工具,并让模型在训练过程中学习使用这些工具。具体来说,我们需要赋予模型访问浏览器的权限,使其能够搜索、点击和滚动页面内容;此外,还需要让它能够执行代码,以进行数据分析和绘制图表等操作。
Deep Research 实战演示
今天我将向大家展示几个Deep Research的应用实例。我们的大多数用户将ChatGPT用于专业场景,例如学术研究、风险投资(据我所知)、咨询等许多其他领域。但同时,也有很多人将其用于个人事务,对我而言,最大的用例可能就是购物和旅行推荐了。接下来,我会展示几个示例查询,以及一些我最近亲自使用的查询。
(切换到屏幕演示)
这就是ChatGPT,相信大家都很熟悉了。
好的,这是一个指令。实际上,我是让ChatGPT帮我写的这个指令:“我今天要红杉人工智能峰会(Sequoia AI Summit)上做一个演讲,我希望能理解并以可视化的方式展示风险资本在人工智能公司投资方面的最新趋势。请分析在多个我想调研的维度上的融资情况。并且,我需要一张能够清晰传达关键趋势的图表。”(我主要是想让大家知道它可以绘制图表,所以这个指令略显刻意。)
点击开始后,Deep Research首先会提出一些澄清性问题。我们这样设计是因为,如果模型要为你工作几分钟,你肯定希望最终得到的输出正是你想要的。我们希望用户能预先提供尽可能详细的信息,鼓励用户表述得非常具体。
它提出了一些问题,我就回答说:“仅限美国”,“两者皆可”,以及“任何一种”。
现在,Deep Research将启动一个研究任务。稍后,我们将能看到它思考链条的概要以及它正在采取的行动。你会看到交错呈现的思考链条——即模型对它遇到的信息源进行推理的过程,以及它进行的工具调用,比如搜索或使用Python工具进行分析。启动过程大约需要一到几分钟。
(等待模型启动)
我这里也有一些预先加载的例子,如果这个启动时间较长,我可以先展示那些。
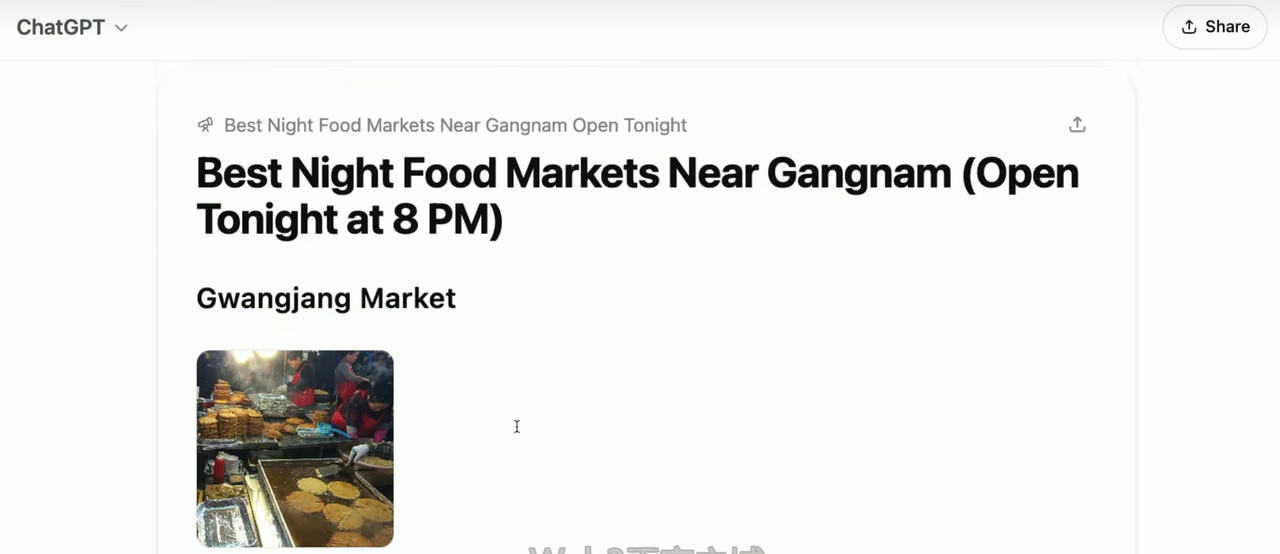
好的,我先展示一个我本周提出的查询,然后再回到刚才那个。本周早些时候,我在韩国,实际上是在手机上进行的这个查询。我想找一个离我所在地最多15分钟路程的夜市,并且希望它能参考Reddit以及我自己看不懂的韩文信息源。然后,在每个符合条件的夜市中,找出评分最高的店铺。大家可以想象,用普通的搜索引擎,很难一次性完成包含所有这些约束条件的搜索。但Deep Research能够搜索网络,并对每个项目进行深度挖掘,判断其是否符合约束条件,然后将所有信息汇总反馈给我。
最终,它给了我一份相当长的报告,推荐了几个可以尝试的夜市。每一项信息都有引文。大家可以看到,这些引文甚至还指出了源材料中与所引用观点相关的具体句子。我最后去了报告中推荐的最后一个夜市。
好,我们回到刚才最初的那个查询。大家可以看到模型正在进行思考。我们刚才也看到了,它的思考过程也会说明它计划做什么,然后它进行了一次搜索,并继续分析。如果你也使用O3,你会知道O3在搜索方面也表现出色。所以,如果你需要的是中等强度的搜索,我推荐使用O3。Deep Research则更适用于耗时较长的深度搜索查询。O3之所以擅长搜索,实际上是因为它也使用了我们为Deep Research开发的相同工具和浏览数据集进行训练。
我现在跳到一个我今天早上运行的例子。这是关于人工智能领域投资格局的最终报告。它绘制了一张图表,我来展示一下。起初我看到这张图表时,以为肯定哪里出错了。但我认为它把OpenAI的投资也计算在内了,所以这张图表看起来非常特别。我就不让大家逐字阅读整个报告了,但希望其中包含一些有价值的洞见,鼓励大家也亲自尝试一下。
我还想展示一下Deep Research广泛的应用场景。这是一个生物学领域的例子,查询的是在美国已获得监管批准、用于治疗血友病的特定基因疗法及其相关信息。模型能够进行研究,然后返回包含引文和详细信息的正确列表。
未来展望:从信息整合到实际行动
我们对Deep Research的持续发展充满期待。它显然还不完美,有时可能会产生“幻觉”(hallucinate)。因此,我们正在努力提升其可靠性。同时,我们也希望能将Deep Research整合到主要的推理模型中。正如大家所知,O3已经具备了良好的搜索能力,我们将继续把研发成果整合到更强大的推理模型中。
此外,我们也非常期待将私有上下文引入Deep Research,例如你们公司的内部知识库、付费信息源等。我认为,对我们而言,下一个重大的发展方向将不仅仅是整合现有信息,更要具备实际执行行动的能力。
结语
非常感谢大家的聆听,接下来我把时间交给Zach。谢谢。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...