
nine-emerging-developer-patterns-for-the-ai-era
Developers are moving past AI as just tooling and starting to treat it as a new foundation for how software gets built. Many of the core concepts we’ve taken for granted — version control, templates, documentation, even the idea of a user — are being rethought in light of agent-driven workflows.
As agents become both collaborators and consumers, we expect to see a shift in foundational developer tools. Prompts can be treated like source code, dashboards can become conversational, and docs are written as much for machines as for humans. Model Context Protocol (MCP) and AI-native IDEs point to a deeper redesign of the development loop itself: we’re not just coding differently, we’re designing tools for a world where agents participate fully in the software loop.
Below, we explore nine forward-looking developer patterns that, although early, are grounded in real pain points and give a hint of what could emerge. These range from rethinking version control for AI-generated code, to LLM-driven user interfaces and documentation.
Let’s dive into each pattern, with examples and insights from the dev community.
1. AI-native Git: Rethinking version control for AI agents
Now that AI agents increasingly write or modify large portions of application code, what developers care about starts to change. We’re no longer fixated on exactly what code was written line-by-line, but rather on whether the output behaves as expected. Did the change pass the tests? Does the app still work as intended?
This flips a long-standing mental model: Git was designed to track the precise history of hand-written code, but, with coding agents, that granularity becomes less meaningful. Developers often don’t audit every diff — especially if the change is large or auto-generated — they just want to know whether the new behavior aligns with the intended outcome. As a result, the Git SHA — once the canonical reference for “the state of the codebase” — begins to lose some of its semantic value.
A SHA tells you that something changed, but not why or whether it’s valid. In AI-first workflows, a more useful unit of truth might be a combination of the prompt that generated the code and the tests that verify its behavior. In this world, the “state” of your app might be better represented by the inputs to generation (prompt, spec, constraints) and a suite of passing assertions, rather than a frozen commit hash. In fact, we might eventually track prompt+test bundles as versionable units in their own right, with Git relegated to tracking those bundles, not just raw source code.
Taking this a step further: In agent-driven workflows, the source of truth may shift upstream toward prompts, data schemas, API contracts, and architectural intent. Code becomes the byproduct of those inputs, more like a compiled artifact than a manually authored source. Git, in this world, starts to function less as a workspace and more as an artifact log — a place to track not just what changed, but why and by whom. We may begin to layer in richer metadata, such as which agent or model made a change, which sections are protected, and where human oversight is required – or where AI reviewers like Diamond can step in as part of the loop.
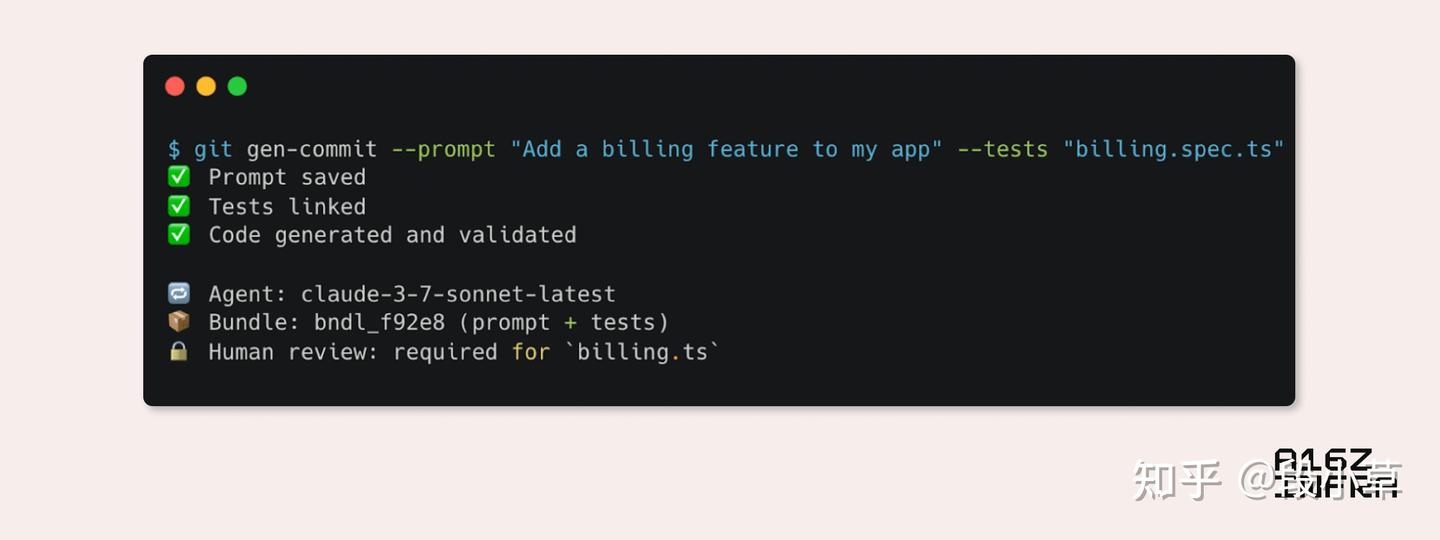
To make this more concrete, below is a mock-up of what an AI-native Git flow could look like in practice:

2. Dashboards -> Synthesis: Dynamic AI-driven interfaces
For years, dashboards have served as the primary interface for interacting with complex systems such as observability stacks, analytics, cloud consoles (think AWS), and more. But their design often suffers from an overloaded UX: too many knobs, charts, and tabs that force users to both hunt for information and figure out how to act on it. Especially for non-power users or across teams, these dashboards can become intimidating or inefficient. Users know what they want to achieve, but not where to look or which filters to apply to get there.
The latest generation of AI models offers a potential shift. Instead of treating dashboards as rigid canvases, we can layer in search and interaction. LLMs can now help users find the right control (“Where can I adjust the rate limiter settings for this API?”); synthesize screen-wide data into digestible insights (“Summarize the error trends across all services in staging over the past 24 hours”); and surface unknown/unknowns (“Given what you know about my business, generate a list of metrics I should pay attention to this quarter”).
We are already seeing technical solutions like Assistant UI that make it possible for agents to leverage React components as tools. Just as content has become dynamic and personalized, UI itself can become adaptive and conversational. A purely static dashboard may soon feel outdated next to a natural language-driven interface that reconfigures based on user intent. For example, instead of clicking through five filters to isolate metrics, a user might say, “Show me anomalies from last weekend in Europe,” and the dashboard reshapes to show that view, complete with summarized trends and relevant logs. Or, even more powerfully, “Why did our NPS score drop last week?”, and the AI might pull up survey sentiment, correlate it with a product deployment, and generate a short diagnostic narrative.
At a larger scale, if agents are now consumers of software, we may also need to rethink what “dashboards” are or for whom they’re designed. For example, dashboards could render views optimized for agent experience — structured, programmatically accessible surfaces designed to help agents perceive system state, make decisions, and act. This might lead to dual-mode interfaces: one human-facing and one agent-facing, both sharing a common state but tailored to different modes of consumption.
In some ways, agents are stepping into roles once filled by alerts, cron jobs, or condition-based automation, but with far more context and flexibility. Instead of pre-wired logic like if error rate > threshold, send alert, an agent might say, “Error rates are rising. Here’s the likely cause, the impacted services, and a proposed fix.” In this world, dashboards aren’t just places to observe; they’re places where both humans and agents collaborate, synthesize, and take action.
How dashboards might evolve to support both human and AI-agent viewers.
3. Docs are becoming a combination of tools, indices, and interactive knowledge bases
Developer behavior is shifting when it comes to documentation. Instead of reading through a table of contents or scanning top-down, users now start with a question. The mental model is no longer “Let me study this spec”, but “Rework this information for me, in a way I like to consume.” This subtle shift — from passive reading to active querying — is changing what docs need to be. Rather than just static HTML or markdown pages, they’re becoming interactive knowledge systems, backed by indices, embeddings, and tool-aware agents.
As a result, we’re seeing the rise of products like Mintlify, which not only structure documentation as semantically searchable databases, but also serve as context sources for coding agents across platforms. Mintlify pages are now frequently cited by AI coding agents — whether in AI IDEs, VS Code extensions, or terminal agents — because coding agents use up-to-date documentation as grounding context for generation.
This changes the purpose of docs: they’re no longer just for human readers, but also for agent consumers. In this new dynamic, the documentation interface becomes something like instructions for AI agents. It doesn’t just expose raw content, but explains how to use a system correctly.

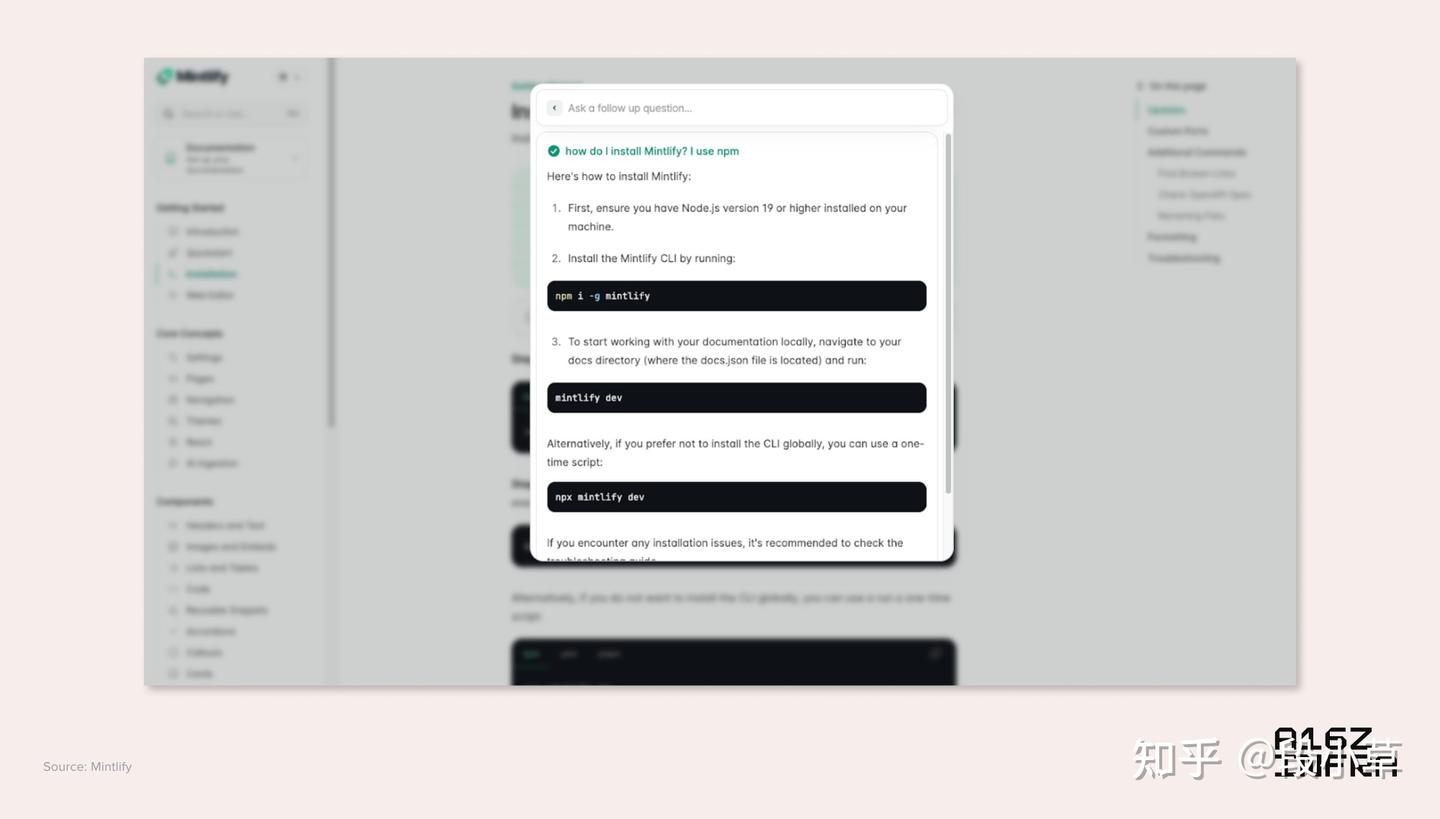
A screenshot from the Mintlify where users can bring up the AI chat window to do Q&A over Mintlify documentations using the cmd+k shortcut
4. Templates to generation: Vibe coding replaces create-react-app
In the past, getting started on a project meant choosing a static template such as a boilerplate GitHub repo or a CLI like create-react-app, next init, or rails new. These templates served as the scaffolding for new apps, offering consistency but little customization. Developers conformed to whatever defaults the framework provided or risked significant manual refactoring.
Now, that dynamic is shifting with the emergence of text-to-app platforms like Replit, Same.dev, Loveable, Chef by Convex, and Bolt, as well as AI IDEs like Cursor. Developers can describe what they want (e.g., “a TypeScript API server with Supabase, Clerk and Stripe”) and have a custom project scaffolded in seconds. The result is a starter that’s not generic, but personalized and purposeful, reflecting both the developer’s intent and their chosen stack.
This unlocks a new distribution model in the ecosystem. Instead of a few frameworks sitting at the head of the long tail, we may see a wider spread of composable, stack-specific generations where tools and architectures are mixed and matched dynamically. It’s less about picking a framework and more about describing an outcome around which the AI can build a stack. One engineer might create an app with Next.js and tRPC, while another starts with Vite and React, but both get working scaffolds instantly.
Of course, there are tradeoffs. Standard stacks bring real advantages, including making teams more productive, improving onboarding, and making troubleshooting easier across orgs. Refactoring across frameworks isn’t just a technical lift; it’s often entangled with product decisions, infrastructure constraints, and team expertise. But what’s shifting is the cost of switching frameworks or starting without one. With AI agents that understand project intent and can execute large refactors semi-autonomously, it becomes much more feasible to experiment — and to reverse course, if needed.
This means framework decisions are becoming much more reversible. A developer might start with Next.js, but later decide to migrate to Remix and Vite, and ask the agent to handle the bulk of the refactor. This reduces the lock-in that frameworks used to impose and encourages more experimentation, especially at early stages of a project. It also lowers the bar for trying opinionated stacks, because switching later is no longer a massive investment.

5. Beyond .env: Managing secrets in an agent-driven world
For decades, .env files have been the default way for developers to manage secrets (e.g., API keys, database URLs, and service tokens) locally. They’re simple, portable, and developer-friendly. But in an agent-driven world, this paradigm begins to break down. It’s no longer clear who owns the .env when an AI IDE or agent is writing code, deploying services, and orchestrating environments on our behalf.
We’re seeing hints of what this could look like. The latest MCP spec, for example, includes an authorization framework based on OAuth 2.1, signaling a possibility to move toward giving AI agents scoped, revocable tokens instead of raw secrets. We can imagine a scenario where an AI agent doesn’t get your actual AWS keys, but instead obtains a short-lived credential or a capability token that lets it perform a narrowly defined action.
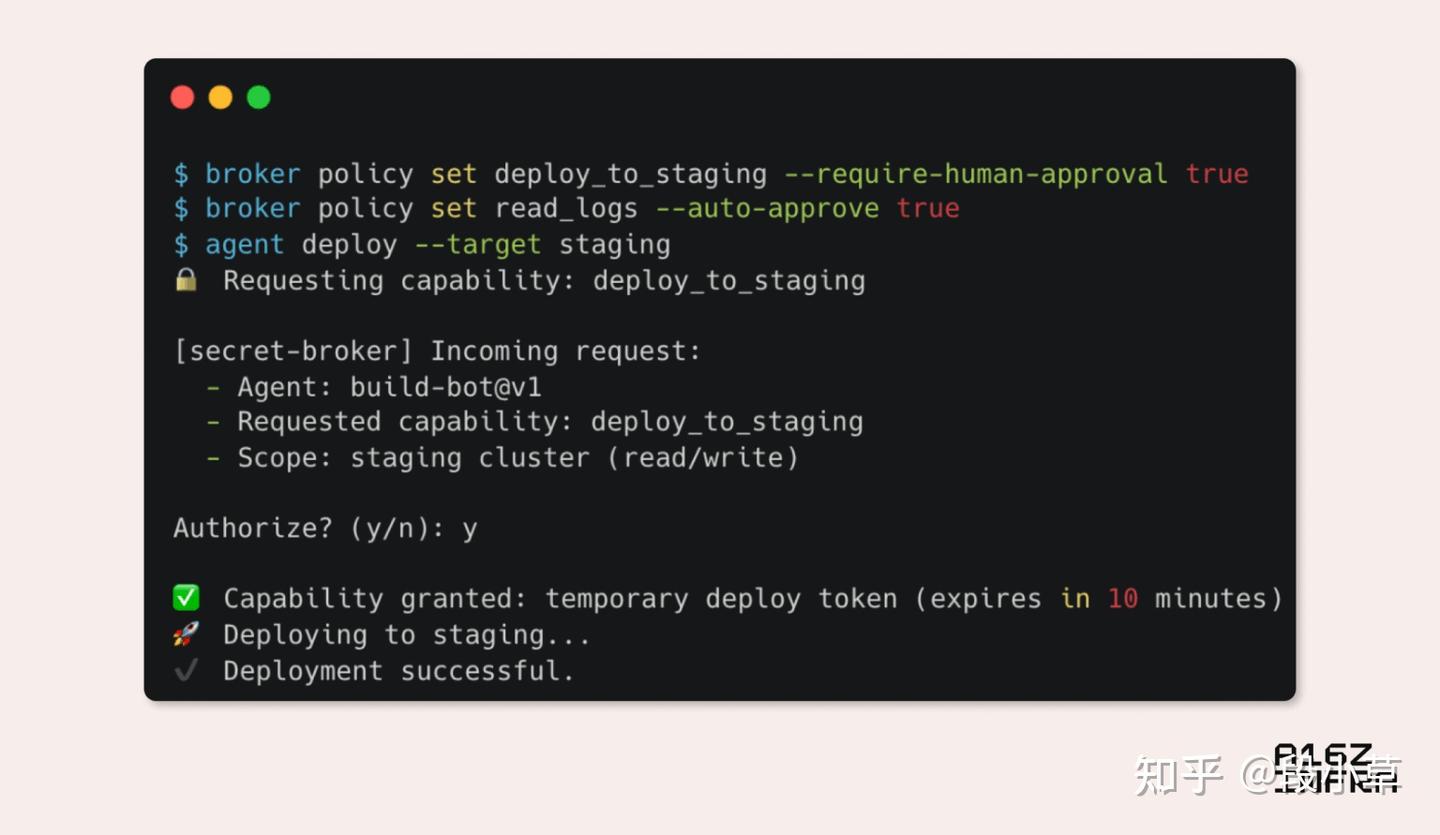
Another way this could shake out is through the rise of local secret brokers — services running on your machine or alongside your app that act as intermediaries between agents and sensitive credentials. Rather than injecting secrets into .env files or hardcoding them into scaffolds, the agent could request access to a capability (“deploy to staging” or “send logs to Sentry”), and the broker determines whether to grant it — just-in-time, and with full auditability. This decouples secret access from the static filesystem, and makes secret management feel more like API authorization than environment configuration.

A CLI mock-up of what the agent-centric secret broker flow could look like.
6. Accessibility as the universal interface: Apps through the eyes of an LLM
We’re starting to see a new class of apps (e.g., Granola and Highlight) that request access to accessibility settings on macOS not for traditional accessibility use cases, but to enable AI agents to observe and interact with interfaces. However, this isn’t a hack: It’s a glimpse into a deeper shift.
Accessibility APIs were built to help users with vision or motor impairments navigate digital systems. But those same APIs, when extended thoughtfully, may become the universal interface layer for agents. Instead of clicking pixel positions or scraping DOMs, agents could observe applications the way assistive tech does — semantically. The accessibility tree already exposes structured elements like buttons, headings, and inputs. If extended with metadata (e.g., intent, role, and affordance), this could become a first-class interface for agents, letting them perceive and act on apps with purpose and precision.
There are a couple potential directions:
- Context extraction: A standard way for an LLM agent using accessibility or semantic APIs to query what’s on screen, what it can interact with, and what the user is doing.
- Intentful execution: Rather than expecting an agent to chain multiple API calls manually, expose a high-level endpoint where it can declare goals (“add an item to the cart, choose fastest shipping”), and let the backend figure out the steps.
- Fallback UI for LLMs: Accessibility features provide a fallback UI for LLMs. Any app that exposes a screen becomes agent-usable, even if it doesn’t have a public API. For developers, it suggests a new “render surface” — not just visual or DOM layers, but agent-accessible context, possibly defined via structured annotations or accessibility-first components.
7. The rise of asynchronous agent work
As developers begin to work alongside coding agents more fluidly, we’re seeing a natural shift toward asynchronous workflows where agents operate in the background, pursue parallel threads of work, and report back when they’ve made progress. This mode of interaction is starting to look less like pair programming and more like task orchestration: you delegate a goal, let the agent run, and check in later.
Crucially, this isn’t just about offloading effort; it also compresses coordination. Instead of pinging another team to update a config file, triage an error, or refactor a component, developers can increasingly assign that task directly to an agent that acts on their intent and executes in the background. What once required sync meetings, cross-functional handoffs, or long review cycles could become an ambient loop of request, generate, and validate.
The surfaces for agent interaction are expanding, too. Instead of always prompting via IDE or CLI, devs could begin to interact with agents by, for example:
- Sending messages to Slack.
- Commenting on Figma mocks.
- Creating inline annotations on code diffs or PRs (e.g. Graphite’s review assistant).
- Adding feedback based on deployed app previews.
- Utilizing voice or call-based interfaces, where devs can describe changes verbally.
This creates a model where agents are present across the full lifecycle of development. They’re not just writing code, but interpreting designs, responding to feedback, and triaging bugs across platforms. The developer becomes the orchestrator who decides which thread to pursue, discard, or merge.
Perhaps this model of branching and delegating to agents becomes the new Git branch — not a static fork of code, but a dynamic thread of intent, running asynchronously until it’s ready to land.
8. MCP is one step closer to becoming a universal standard
We recently published a deep dive on MCP. Since then, momentum has accelerated: OpenAI publicly adopted MCP, several new features of the spec were merged, and toolmakers are starting to converge around it as the default interface between agents and the real world.
At its core, MCP solves two big problems:
- It gives an LLM the right set of context to complete tasks it may have never seen.
- It replaces N×M bespoke integrations with a clean, modular model in which tools expose standard interfaces (servers) usable by any agents (clients).
We expect to see broader adoption as remote MCP and a de-facto registry come online. And, over time, apps may begin shipping with MCP surfaces by default.
Think of how APIs enabled SaaS products to plug into each other and compose workflows across tools. MCP could do the same for AI agents by turning standalone tools into interoperable building blocks. A platform that ships with an MCP client baked in isn’t just “AI-ready,” but is part of a larger ecosystem, instantly able to tap into a growing network of agent-accessible capabilities.
Additionally, MCP clients and servers are logical barriers, not physical boundaries. This means any client can also act as a server, and vice versa. This could theoretically unlock a powerful level of composability via which an agent using an MCP client to consume context can also expose its own capabilities via a server interface. For example, a coding agent could act as a client to fetch GitHub issues, but also register itself as a server that exposes test coverage or code analysis results to other agents.
9. Abstracted primitives: Every AI agent needs auth, billing, and persistent storage
As vibe coding agents get more powerful, one thing becomes clear: Agents can generate a lot of code, but they still need something solid to plug into. Just like human developers lean on Stripe for payments, Clerk for auth, or Supabase for database capabilities, agents need similarly clean and composable service primitives to scaffold reliable applications.
In many ways, these services — APIs with clear boundaries, ergonomic SDKs, and sane defaults that reduce the chance of failure — are increasingly serving as the runtime interface for agents. If you’re building a tool that generates a SaaS app, you don’t want your agent to roll its own auth system or write billing logic from scratch; you want it to use providers like Clerk and Stripe.
As this pattern matures, we may start to see services optimize themselves for agent consumption by exposing not just APIs, but also schemas, capability metadata, and example flows that help agents integrate them more reliably.
Some services might even start shipping with MCP servers by default, turning every core primitive into something agents can reason about and use safely out of the box. Imagine Clerk exposing an MCP server that lets an agent query available products, create new billing plans, or update a customer’s subscription — all with permission scopes and constraints defined up front. Instead of hand-authoring API calls or hunting through docs, an agent could say, “Create a monthly ‘Pro’ plan at $49 with usage-based overages,” and Clerk’s MCP server would expose that capability, validate the parameters, and handle the orchestration securely.
Just as the early web era needed Rails generators and rails new to move fast, the agent era needs trustworthy primitives — drop-in identity, usage tracking, billing logic, and access control — all abstracted enough to generate against, but expressive enough to grow with the app.
Conclusion
These patterns point to a broader shift in which new developer behaviors are emerging alongside more capable foundation models. And, in response, we’re seeing new toolchains and protocols like MCP take shape. It’s not just AI layered onto old workflows, but is a redefinition of how software gets built with agents, context, and intent at the core. Many developer-tooling layers are fundamentally shifting, and we are excited to build and invest in the next generation of tools.
AI 时代九大新兴开发者模式
开发者正在超越将 AI 仅仅视为工具的阶段,开始将其视为软件构建方式的新基础。许多我们习以为常的核心概念——版本控制、模板、文档,甚至用户的概念——都在 AI 智能体(AI agent)驱动的工作流背景下被重新思考。
随着 AI 智能体 同时成为协作者和消费者,我们预计基础开发者工具将发生转变。提示词(Prompts)可以像源代码一样被对待,仪表板可以变得具有对话性,文档的编写既面向机器也面向人类。Model Context Protocol (MCP) 和 AI 原生 IDE 指向了开发循环本身的更深层次重新设计:我们不仅在以不同的方式编码,我们还在为一个 AI 智能体 完全参与软件循环的世界设计工具。
下面,我们将探讨九种前瞻性的开发者模式,尽管它们尚处于早期阶段,但都源于实际痛点,并预示了可能出现的趋势。这些模式涵盖了从重新思考 AI 生成代码的版本控制,到由 大语言模型(LLM)驱动的用户界面和文档等多个方面。
1. AI 原生 Git:为 AI 智能体重新思考版本控制
既然 AI 智能体 越来越多地编写或修改应用程序代码的大部分内容,开发者关心的重点开始发生变化。我们不再执着于逐行精确地记录编写了什么代码,而是更关注输出是否符合预期行为。变更是否通过了测试?应用程序是否仍然按预期工作?
这颠覆了一个长期存在的思维模式:Git 被设计用来跟踪手动编写代码的精确历史,但随着 AI 编程智能体的出现,这种粒度变得不那么重要。开发者通常不会审计每一个 diff——尤其是在变更很大或是自动生成的情况下——他们只想知道新的行为是否与预期结果一致。因此,Git SHA——曾经是“代码库状态”的规范性引用——开始失去部分语义价值。
一个 SHA 告诉你某些东西发生了变化,但并未说明原因或其是否有效。在 AI 优先的工作流中,一个更有用的真值单元可能是生成代码的 提示词 和验证其行为的测试的组合。在这个世界里,你的应用程序的“状态”可能更好地由生成输入(提示词、规范、约束)和一套通过的断言来表示,而不是一个冻结的 commit hash。事实上,我们最终可能会将 prompt+test 捆绑包作为其自身可版本化的单元进行跟踪,而 Git 则降级为跟踪这些捆绑包,而不仅仅是原始源代码。
更进一步:在 AI 智能体 驱动的工作流中,事实的来源可能会向上游转移到 提示词、数据模式、API 契约和架构意图。代码成为这些输入的副产品,更像是编译后的构件,而不是手动编写的源。在这个世界里,Git 开始更多地扮演构件日志的角色,而不是工作区——一个不仅跟踪发生了什么变化,还跟踪变化原因和执行者的场所。我们可能会开始加入更丰富的元数据,例如哪个 AI 智能体 或模型进行了更改,哪些部分受到保护,以及哪里需要人工监督——或者像 Diamond 这样的 AI 审查者可以在循环中介入。
为了更具体地说明这一点,下面是一个 AI 原生 Git 流程在实践中可能呈现的示意图:
2. 仪表板 -> 综合分析:动态 AI 驱动的界面
多年来,仪表板一直是与复杂系统(如可观测性堆栈、分析工具、云控制台(例如 AWS)等)交互的主要界面。但它们的设计常常受到过载 UX 的困扰:太多的旋钮、图表和标签页迫使用户既要寻找信息,又要弄清楚如何根据信息采取行动。特别是对于非高级用户或跨团队用户而言,这些仪表板可能令人望而生畏或效率低下。用户知道他们想要实现什么,但不知道去哪里查找或应用哪些过滤器来实现目标。
最新一代的 AI 模型提供了一个潜在的转变。我们可以不再将仪表板视为僵化的画布,而是加入搜索和交互层。大语言模型(LLMs)现在可以帮助用户找到正确的控件(「我在哪里可以调整这个 API 的速率限制器设置?」);将整个屏幕的数据综合成易于理解的见解(「总结过去 24 小时内 staging 环境中所有服务的错误趋势」);并揭示未知的未知(「根据你对我的业务的了解,生成一份我本季度应该关注的指标列表」)。
我们已经看到像 Assistant UI 这样的技术解决方案,使得 AI 智能体 能够利用 React 组件作为工具。正如内容变得动态化和个性化一样,UI 本身也可以变得自适应和对话式。一个纯粹静态的仪表板可能很快就会在自然语言驱动、根据用户意图重新配置的界面旁边显得过时。例如,用户可能不再需要点击五个过滤器来分离指标,而是可以说:「显示上周末欧洲的异常情况」,然后仪表板会重塑以显示该视图,并附带总结的趋势和相关日志。或者,更强大的是,用户问:「为什么我们的 NPS 分数上周下降了?」,AI 可能会调取调查情绪,将其与产品部署关联起来,并生成一个简短的诊断叙述。
在更大范围内,如果 AI 智能体 现在是软件的消费者,我们可能还需要重新思考“仪表板”是什么,或者它们是为谁设计的。例如,仪表板可以渲染为 AI 智能体 体验优化的视图——结构化的、可通过编程访问的界面,旨在帮助 AI 智能体 感知系统状态、做出决策并采取行动。这可能导致双模式界面:一个面向人类,一个面向 AI 智能体,两者共享一个共同的状态,但针对不同的消费模式进行了定制。
在某些方面,AI 智能体 正在扮演曾经由警报、cron jobs 或基于条件的自动化所扮演的角色,但具有更丰富的上下文和灵活性。AI 智能体 可能不再是执行预设逻辑,例如「如果错误率 > 阈值,则发送警报」,而是会说:「错误率正在上升。这可能是原因,受影响的服务以及建议的修复方案。」在这个世界里,仪表板不仅仅是观察的地方;它们是人类和 AI 智能体 协作、综合信息并采取行动的地方。
3. 文档正在成为工具、索引和交互式知识库的结合体
开发者在处理文档方面的行为正在发生转变。用户现在不再是通读目录或自上而下浏览,而是从一个问题开始。思维模式不再是「让我研究一下这个规范」,而是「以我喜欢的方式为我重塑这些信息」。这种从被动阅读到主动查询的微妙转变正在改变文档应有的形态。它们不再仅仅是静态的 HTML 或 markdown 页面,而是正在成为由索引、嵌入和具备工具感知能力的 AI 智能体 支持的交互式知识系统。
因此,我们看到像 Mintlify 这样的产品正在兴起,它们不仅将文档构建为可语义搜索的数据库,而且还作为跨平台 AI 编程 智能体的上下文来源。Mintlify 页面现在经常被 AI 编程 智能体引用——无论是在 AI IDE 中、VS Code 扩展中,还是在终端 AI 智能体 中——因为 AI 编程 智能体使用最新的文档作为生成的基础上下文。
这改变了文档的目的:它们不再仅仅是为人类读者准备的,也是为 AI 智能体 消费者准备的。在这种新的动态中,文档界面变得有点像给 AI 智能体 的指令。它不仅暴露原始内容,还解释了如何正确使用一个系统。
4. 从模板到生成:氛围编程(Vibe coding)取代 create-react-app
在过去,启动一个项目意味着选择一个静态模板,例如样板 GitHub 仓库或像 create-react-app、next init 或 rails new 这样的 CLI。这些模板为新应用提供了脚手架,提供了一致性但定制性很小。开发者要么遵循框架提供的任何默认设置,要么冒着进行大量手动重构的风险。
现在,随着像 Replit、Same.dev、Loveable、Chef by Convex 和 Bolt 这样的文本到应用平台,以及像 Cursor 这样的 AI IDE 的出现,这种动态正在发生转变。开发者可以描述他们想要什么(例如,「一个使用 Supabase、Clerk 和 Stripe 的 TypeScript API 服务器」),并在几秒钟内搭建好一个定制的项目脚手架。结果是一个非通用的、个性化且有目的的启动器,反映了开发者的意图和他们选择的技术栈。
这在生态系统中解锁了一种新的分发模式。不再局限于少数框架占据长尾顶端,我们可能会看到更广泛分布的可组合、针对特定技术栈的世代,其中工具与架构被动态地混合搭配。这不再是关于选择一个框架,更多是关于描述一个结果,AI 可以围绕这个结果构建一个技术栈。一个工程师可能使用 Next.js 和 tRPC 创建一个应用,而另一个则从 Vite 和 React 开始,但两者都能立即获得可工作的脚手架。
当然,这里存在权衡。标准技术栈带来了实际优势,包括提高团队生产力、改善入职流程以及简化跨组织的故障排除。跨框架重构不仅仅是技术上的提升;它常常与产品决策、基础设施限制和团队专业知识纠缠在一起。但正在发生变化的是切换框架或不使用框架启动的成本。有了能够理解项目意图并能半自主执行大型重构的 AI 智能体,进行实验变得更加可行——并且在需要时可以逆转方向。
这意味着框架决策变得更加可逆。开发者可能开始使用 Next.js,但后来决定迁移到 Remix 和 Vite,并要求 AI 智能体 处理大部分重构工作。这减少了框架过去常常施加的锁定效应,并鼓励更多的实验,尤其是在项目的早期阶段。这也降低了尝试特定技术栈的门槛,因为稍后切换不再是一项巨大的投资。

5. 超越 .env:在 AI 智能体驱动的世界中管理密钥
几十年来,.env 文件一直是开发者在本地管理密钥(例如 API 密钥、数据库 URL 和服务令牌)的默认方式。它们简单、可移植且对开发者友好。但在一个 AI 智能体 驱动的世界里,这种范式开始瓦解。当一个 AI IDE 或 AI 智能体 代表我们编写代码、部署服务和编排环境时,.env 的所有权归属变得不再清晰。
我们正在看到一些迹象表明这可能是什么样子。例如,最新的 MCP 规范包含一个基于 OAuth 2.1 的授权框架,这预示着可能转向给予 AI 智能体 范围受限、可撤销的令牌,而不是原始机密。我们可以想象这样一个场景:一个 AI 智能体 不会得到你实际的 AWS 密钥,而是获得一个短期的凭证或能力令牌,允许它执行一个狭义定义的操作。
另一种可能的方式是通过本地机密代理的兴起——这些服务运行在你的机器上或与你的应用并行,充当 AI 智能体 和敏感凭证之间的中介。AI 智能体 不再需要将机密注入 .env 文件或硬编码到脚手架中,而是可以请求访问某个能力(例如「部署到 staging」或「发送日志到 Sentry」),然后由代理决定是否授予访问权限——实时授予,并具有完全的可审计性。这将机密访问与静态文件系统解耦,使得机密管理感觉更像是 API 授权,而不是环境配置。
6. 可访问性作为通用接口:通过大语言模型的视角看应用
我们开始看到一类新的应用程序(例如 Granola 和 Highlight),它们请求访问 macOS 上的可访问性设置,并非用于传统的可访问性用例,而是为了让 AI 智能体 能够观察和与界面交互。然而,这并非一种取巧手段:它揭示了一个更深层次的转变。
可访问性 API 最初是为了帮助有视觉或运动障碍的用户导航数字系统而构建的。但是,如果经过深思熟虑的扩展,这些相同的 API 可能会成为 AI 智能体 的通用接口层。AI 智能体 不再需要点击像素位置或抓取 DOM,而是可以像辅助技术那样——以语义化的方式观察应用程序。可访问性树已经暴露了结构化元素,如按钮、标题和输入框。如果用元数据(例如意图、角色和功能可见性)进行扩展,这可能成为 AI 智能体 的一流接口,让它们能够有目的地、精确地感知应用程序并采取行动。
有几个潜在的方向:
- 上下文提取:为使用可访问性或语义 API 的 大语言模型(LLM)AI 智能体 提供一种标准方式,以查询屏幕上有什么、它可以与什么交互以及用户正在做什么。
- 意图执行:与其期望 AI 智能体 手动链接多个 API 调用,不如暴露一个高级端点,让它可以声明目标(「将商品添加到购物车,选择最快配送」),并让后端找出执行步骤。
- 面向大语言模型的后备 UI:可访问性功能为 大语言模型 提供了一个后备 UI。任何暴露屏幕的应用,即使没有公共 API,也变得可供 AI 智能体 使用。对于开发者来说,这提示了一个新的「渲染表面」——不仅仅是视觉或 DOM 层,而是 AI 智能体 可访问的上下文,可能通过结构化注释或可访问性优先的组件来定义。
7. 异步 AI 智能体工作的兴起
随着开发者开始更流畅地与 AI 编程 智能体协同工作,我们看到向异步工作流的自然转变,其中 AI 智能体 在后台运行,执行并行工作线程,并在取得进展时进行汇报。这种交互模式开始变得不那么像结对编程,而更像是任务编排:你委派一个目标,让 AI 智能体 运行,稍后再检查结果。
关键在于,这不仅仅是为了分担工作量;它还压缩了协调过程。开发者不再需要联系另一个团队来更新配置文件、分类错误或重构组件,而是可以越来越多地将任务直接分配给一个根据他们的意图行事并在后台执行的 AI 智能体。过去需要同步会议、跨职能交接或漫长审查周期的工作,可能会变成一个请求、生成和验证的环境循环。
AI 智能体 交互的界面也在扩展。开发者不再总是通过 IDE 或 CLI 发出 提示词,而是可以开始通过以下方式与 AI 智能体 交互,例如:
- 向 Slack 发送消息。
- 在 Figma 模型上发表评论。
- 在代码 diffs 或 PRs 上创建内联注释(例如 Graphite 的审查助手)。
- 基于已部署的应用预览添加反馈。
- 利用语音或基于通话的界面,开发者可以口头描述变更。
这构建了一种 AI 智能体贯穿开发全生命周期的模式。它们不仅仅是编写代码,还在跨平台解释设计、响应反馈和分类错误。开发者成为编排者,决定追求、丢弃或合并哪个线程。
也许这种分支并将任务委派给 AI 智能体 的模型会成为新的 Git 分支——不是代码的静态分支,而是一个动态的意图线程,异步运行直到准备好合并。
8. MCP 距离成为通用标准又近了一步
我们最近发布了关于 MCP 的深度剖析。自那时以来,发展势头加速:OpenAI 公开采用了 MCP,该规范的几项新特性已被合并,工具制造商开始将其视为 AI 智能体 与现实世界之间的默认接口并趋于一致。
MCP 的核心解决了两大问题:
- 它为 大语言模型 提供了正确的上下文集合,以完成它可能从未见过的任务。
- 它用一个简洁、模块化的模型取代了 N×M 个定制集成,在该模型中,工具暴露可供任何 AI 智能体(客户端)使用的标准接口(服务器)。
我们预计随着远程 MCP 和事实上的注册中心的上线,将会看到更广泛的采用。并且,随着时间的推移,应用程序可能会开始默认搭载 MCP 界面。
想想 API 如何使 SaaS 产品能够相互连接并在不同工具间组合工作流。MCP 可以通过将独立工具转变为可互操作的构建块,为 AI 智能体 实现同样的目标。一个内置了 MCP 客户端的平台不仅仅是「为 AI 做好准备」,而是更大生态系统的一部分,能够立即接入不断增长的 AI 智能体 可访问能力网络。
此外,MCP 客户端和服务器是逻辑屏障,而非物理边界。这意味着任何客户端也可以充当服务器,反之亦然。理论上,这可以解锁强大的可组合性,使得使用 MCP 客户端消费上下文的 AI 智能体 也能通过服务器接口暴露自身的能力。例如,一个 AI 编程 智能体可以作为客户端获取 GitHub 问题,但同时也可以将自己注册为服务器,向其他 AI 智能体 暴露测试覆盖率或代码分析结果。
9. 抽象原语:每个 AI 智能体都需要 auth、计费和持久化存储
随着 氛围编程(vibe coding)AI 智能体 的日益强大,有一点变得清晰:AI 智能体 可以生成大量代码,但它们仍然需要一些坚实的基础来接入。就像人类开发者依赖 Stripe 处理支付、Clerk 处理 auth、或 Supabase 提供数据库能力一样,AI 智能体 也需要类似简洁且可组合的服务原语来构建可靠的应用程序。
在许多方面,这些服务——具有清晰边界的 API、符合人体工程学的 SDK 以及减少失败几率的合理默认值——正日益成为 AI 智能体 的运行时接口。如果你正在构建一个生成 SaaS 应用的工具,你不会希望你的 AI 智能体 自己构建 auth 系统或从头编写计费逻辑;你会希望它使用像 Clerk 和 Stripe 这样的提供商。
随着这种模式的成熟,我们可能会开始看到服务通过不仅暴露 API,还暴露模式、能力元数据和示例流程来为 AI 智能体 消费进行自我优化,以帮助 AI 智能体 更可靠地集成它们。
一些服务甚至可能开始默认搭载 MCP 服务器,将每个核心原语转变为 AI 智能体 可以推理并安全地开箱即用的东西。想象一下 Clerk 暴露一个 MCP 服务器,允许一个 AI 智能体 查询可用产品、创建新的计费计划或更新客户的订阅——所有这些都预先定义了权限范围和约束。AI 智能体 不再需要手动编写 API 调用或在文档中搜索,而是可以说:「创建一个每月 49 美元的‘Pro’计划,包含基于用量的超额费用」,而 Clerk 的 MCP 服务器将暴露该能力,验证参数,并安全地处理编排。
正如早期 Web 时代需要 Rails 生成器和 rails new 来快速发展一样,AI 智能体 时代需要值得信赖的原语——即插即用的身份认证、使用情况跟踪、计费逻辑和访问控制——所有这些都足够抽象以便于生成,同时又足够富有表现力以适应应用的增长。
结论
这些模式指向了一个更广泛的转变,即新的开发者行为正随着更强大的基础模型的出现而涌现。作为回应,我们看到像 MCP 这样的新工具链和协议正在形成。这不仅仅是将 AI 叠加在旧的工作流之上,而是以 AI 智能体、上下文和意图为核心,对软件构建方式的重新定义。许多开发者工具层正在发生根本性转变,我们对构建和投资下一代工具感到兴奋。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...