您当前未登录!建议登陆后购买,可保存购买订单。
免费更新
客服服务
风险投资家、“互联网女王” 玛丽・米克尔(Mary Meeker)联合创立了 BOND Capital,延续了米克尔在凯鹏华盈及摩根士丹利期间每年发布备受瞩目的《互联网趋势》报告的传统。2025 年 5 月,BOND 发布了《趋势–人工智能 (AI)》报告,展示了其对颠覆性技术趋势的敏锐洞察。
BOND 是一家科技投资公司,它致力于在创新和增长的整个生命周期中,为有远见的创始人提供支持。其创始合伙人拥有丰富的行业经验,曾成功投资并支持了众多改变世界的科技公司,如 Airbnb、AlphaSense、Applied Intuition、Canva、DocuSign、DoorDash、KoBold Metals、Meta(Facebook)、Instacart、Peloton、Plaid、Revolut、Slack、Spotify、Square、Stripe、Twitter、Uber 和 VAST Data 等。
我们着手整理与人工智能相关的基础性发展趋势。最初收集的一些零散的数据点最终演变成了这份内容丰富的报告。
我们刚更新完一张图表,往往就得更新另一张 —— 这就像是一场打地鼠的数据游戏……
这种情况毫无停止的迹象…… 而且随着科技领域的老牌企业、新兴挑战者以及各国之间的竞争加剧,情况还会变得更加复杂。
“互联网之父” 之一的文顿・瑟夫在 1999 年曾说:“…… 人们说在互联网行业,一年就像狗的一年 —— 相当于普通人生活中的七年。” 当时,互联网引发的变革速度是前所未有的。
在英语中,“a dog year” 常用来表示 “狗狗的一年”,源于 “狗狗年龄换算成人的年龄” 的传统说法,通常认为狗的 1 年相当于人类的 7 年。
如今再想想,人工智能用户数量和使用情况的增长速度实际上要快得多…… 而且机器的发展速度能超过我们。
与人工智能技术演进相关的变革速度和范围确实是史无前例的,这些数据就是证明。这份文件里满是呈现出向右上方增长趋势的用户数量、使用情况以及营收图表…… 而且往往还有同样呈向右上方增长趋势的支出图表作为支撑。
创作者、投资者和消费者正在利用全球互联网基础设施,55 亿人可以通过联网设备接入这一设施;过去三十多年来一直在不断积累的日益庞大的数字数据集;以及具有突破性的大型语言模型(LLMs)—— 实际上,随着 2022 年 11 月 OpenAI 的 ChatGPT 推出,凭借其极其易用且快速的用户界面,大型语言模型获得了新的发展空间。
此外,相对较新的人工智能公司的创始人在创新、产品发布、投资、收购、资金消耗和融资方面表现得尤为积极。与此同时,更多传统科技公司(通常有创始人参与其中)也越来越多地将其可观的自由现金流投入到人工智能领域,以推动增长并抵御竞争对手。
而且全球竞争 —— 尤其是中美两国在科技发展方面的竞争 —— 十分激烈。
我们这份文件的大纲在下一页,随后是十一张图表,它们有助于阐述接下来的观察结果。
我们希望这份汇编资料能为有关正在发生的广泛变革(包括技术、金融、社会、物质和地缘政治等方面)的讨论增添新的内容。
毫无疑问,随着我们都努力适应这一不断发展的进程,人们(以及机器)会对这些观点加以完善,因为知识及其传播正以新的方式迅速提升。
特别感谢格兰特・沃森、基扬・桑贾萨兹以及 BOND 的同事们,他们帮助梳理思路并使这份报告得以完成。
同时,也感谢众多以直接或通过自身工作给予帮助、推动科技进步的朋友和技术开发者们。

1. 看起来变化发生得比以往任何时候都要快吗?是的!
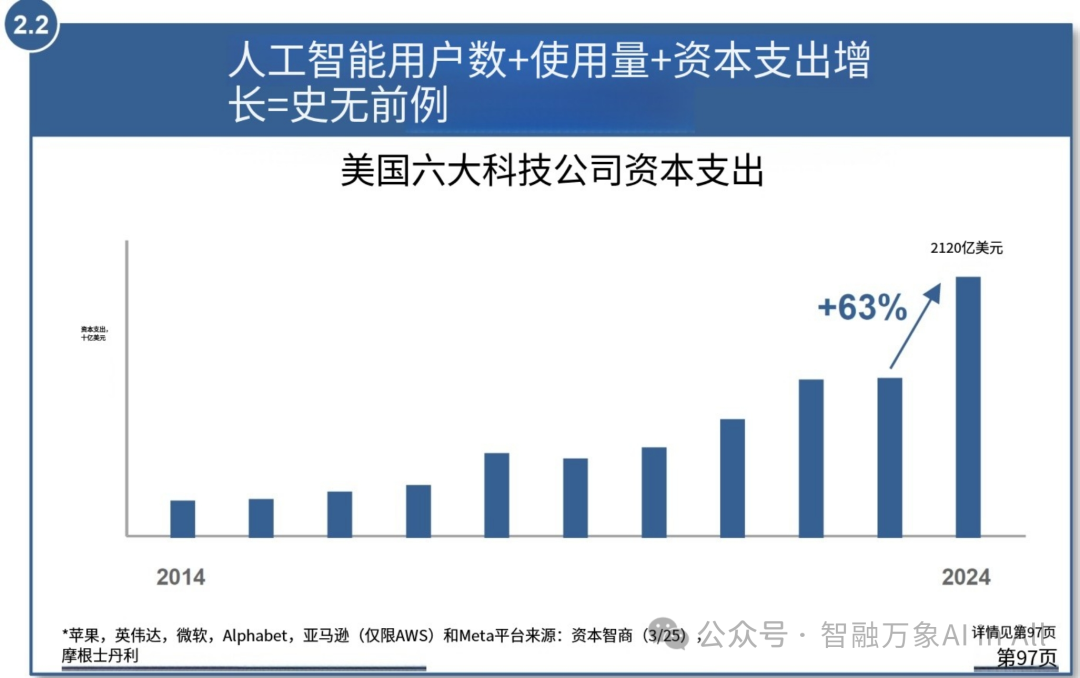
2. 人工智能用户数量 + 使用情况 + 资本支出增长 = 前所未有的
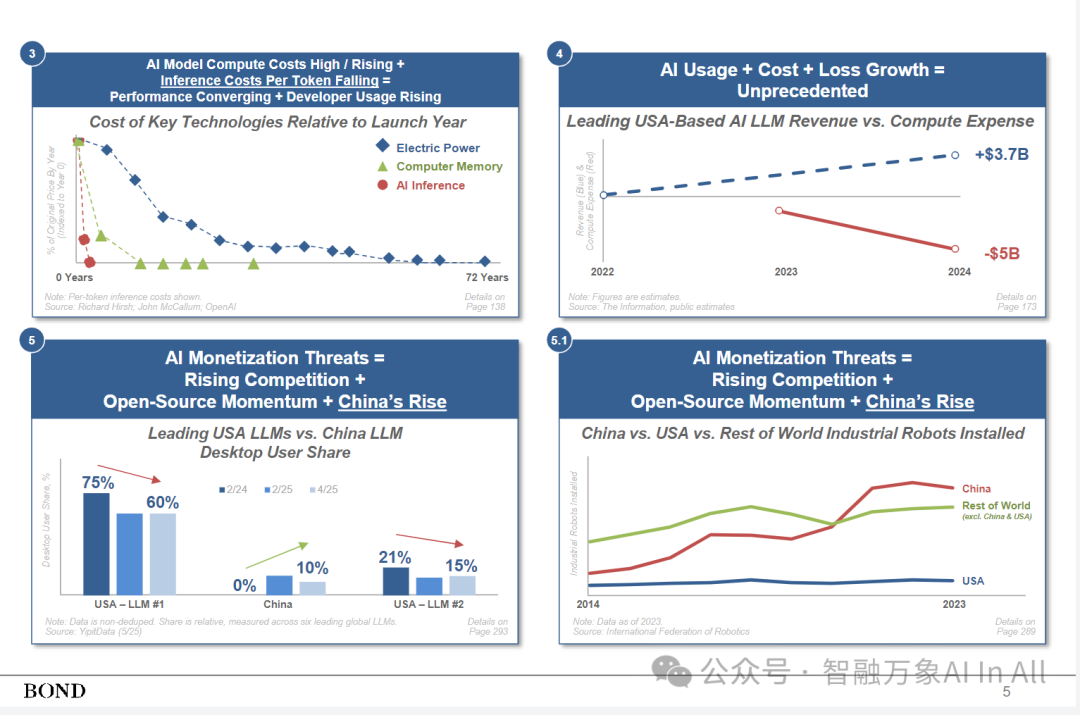
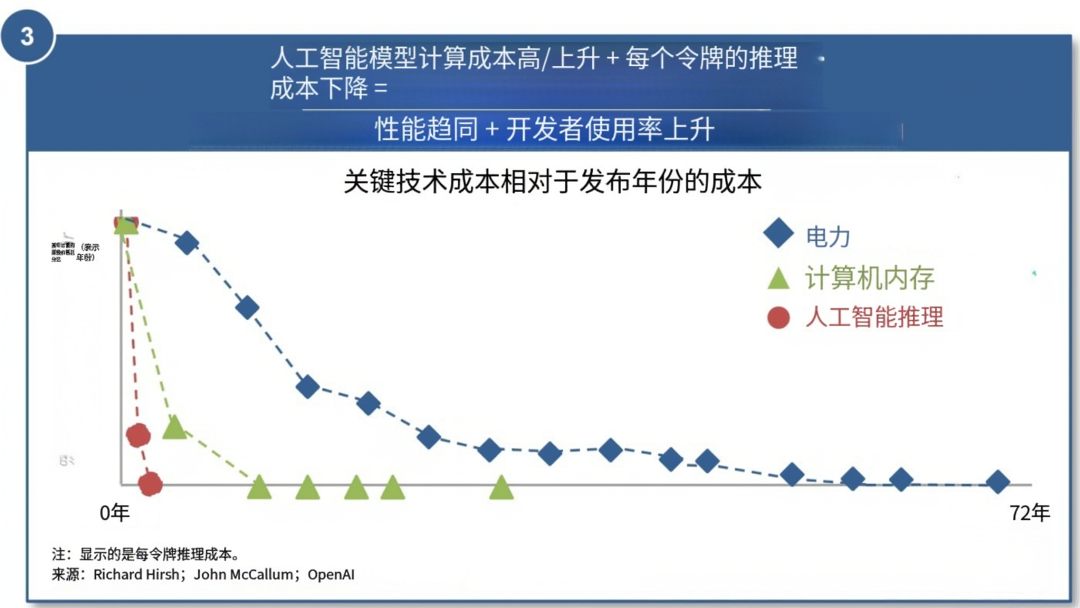
3. 人工智能模型的计算成本高昂且不断上升,同时每个token的推理成本却在下降,这意味着 = 性能趋于一致 + 开发者使用量上升
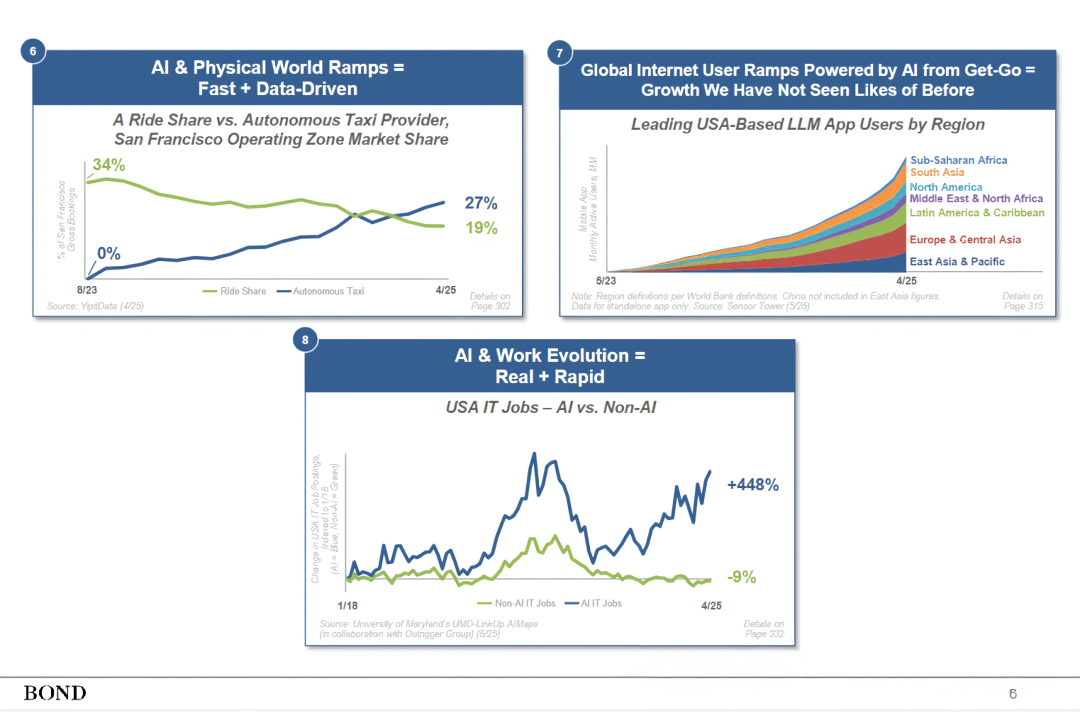
4. 人工智能使用量 + 成本 + 损失的增长 = 前所未有的
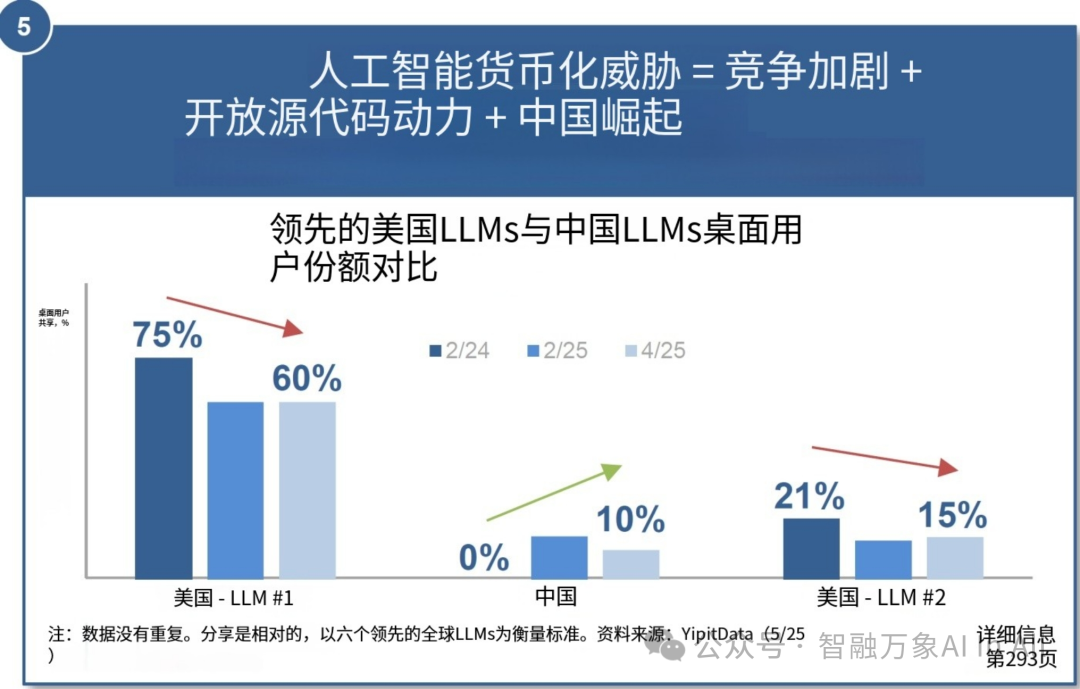
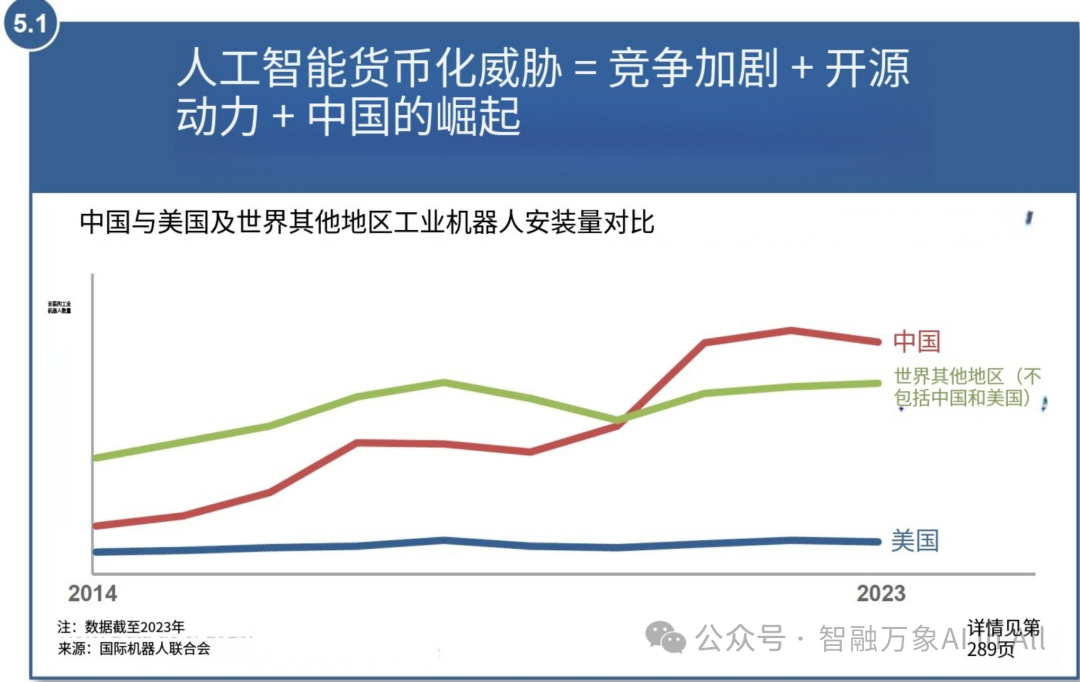
5. 人工智能商业化面临的威胁 = 竞争加剧 + 开源的发展 + 中国的崛起
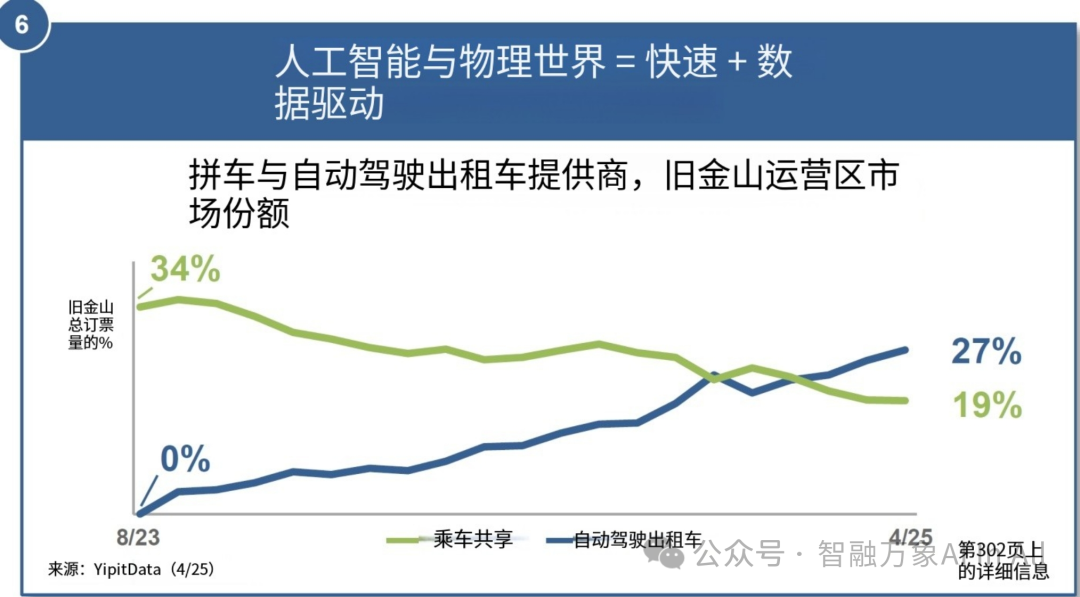
6. 人工智能与现实物理世界的融合 = 快速 + 数据驱动
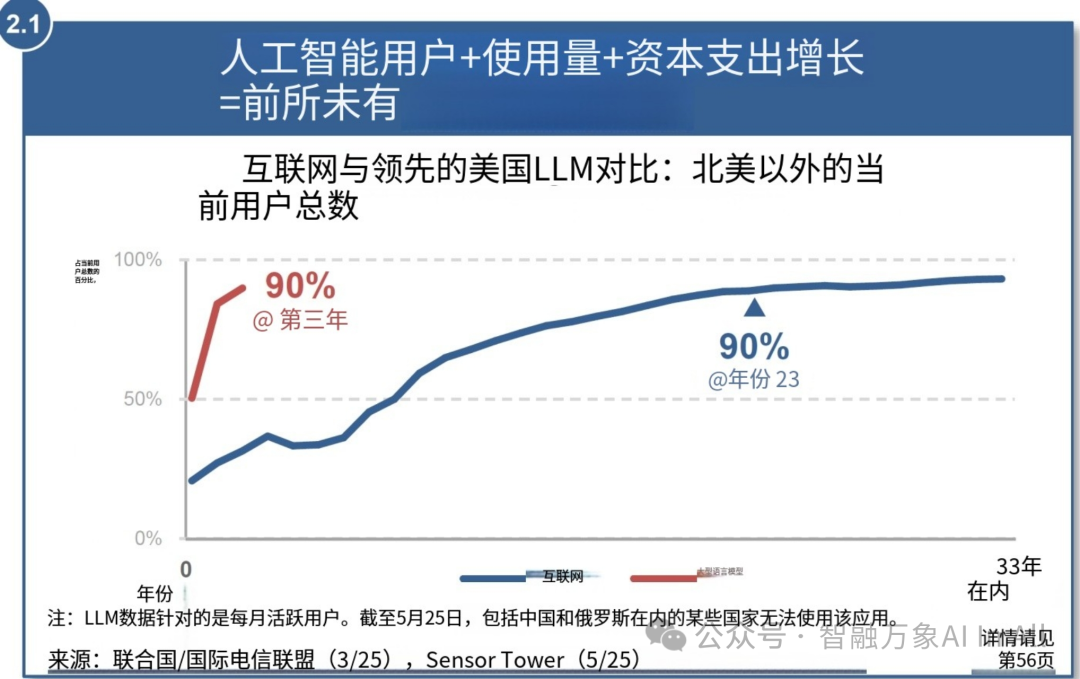
7. 人工智能的全球互联网用户数量的增长 = 我们前所未见的增长
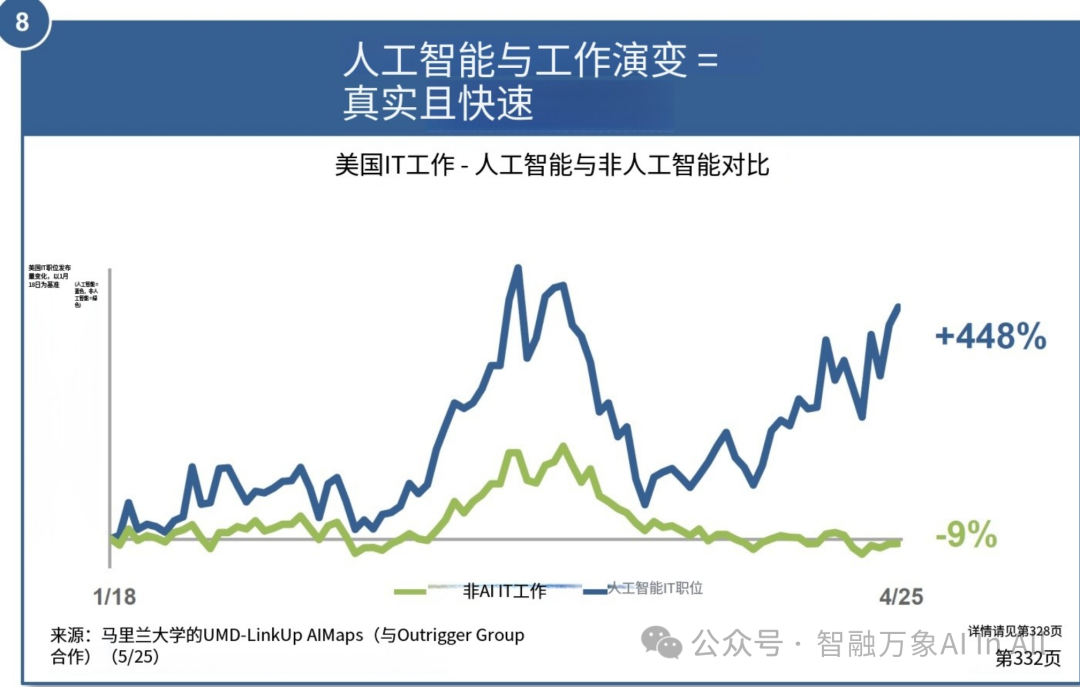
8. 人工智能融合工作的演进 = 真实 + 迅速
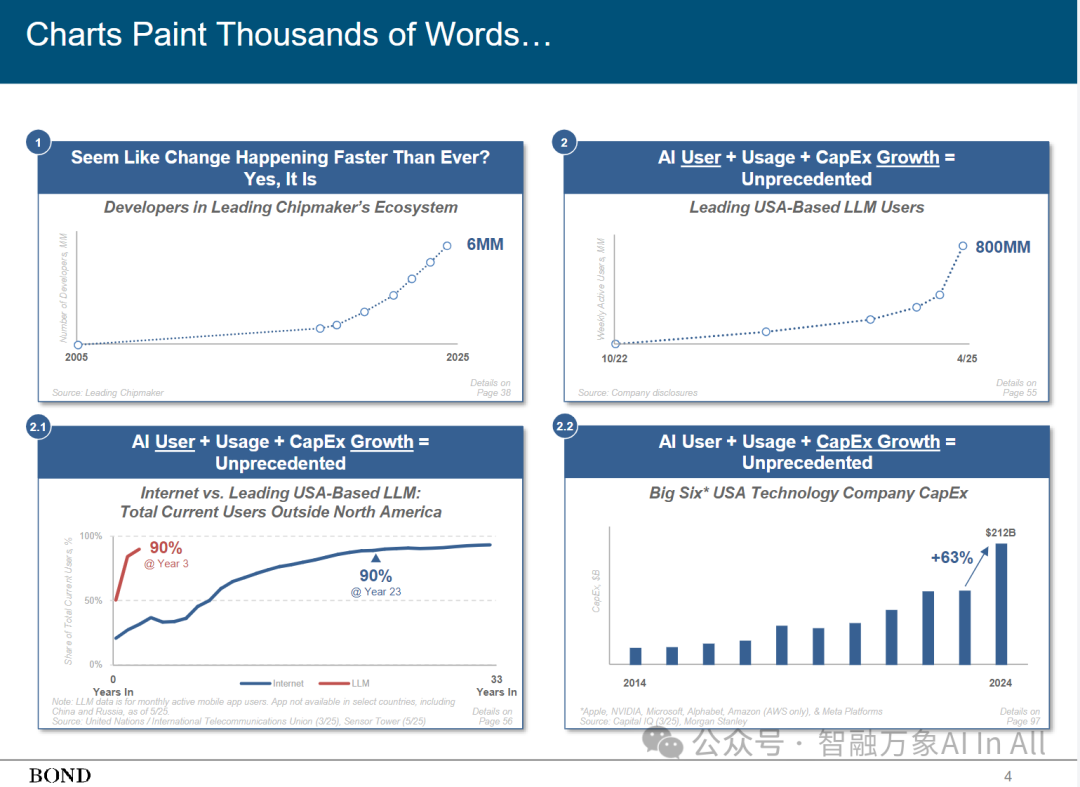
图表胜过千言万语……

说世界正以前所未有的速度变化,都算是轻描淡写了。
快速且具变革性的技术创新与应用,是这些变化的关键支撑。
全球大国的领导力演变也是如此。
谷歌(1998 年)的创始使命是 “整理全球信息,使其能被普遍获取并发挥效用” 。
阿里巴巴(1999 年)的创始使命是 “让天下没有难做的生意” 。
脸书(2004 年)的创始使命是 “赋予人们分享的力量,让世界更开放、更紧密相连” 。
快进到今天,经人工智能赋能、计算能力加速提升以及近乎无边界的资本助力,全球有序化、互联互通且可获取的信息正得到极大增强…… 所有这些都在推动大规模变革。
体育赛事可很好地类比人工智能的持续进步。就像运动员不断带给我们惊喜、打破纪录,他们的天赋正因更优质的数据、投入和训练而日益得到强化。
企业也是如此,计算机正吸纳海量数据集,变得更智能、更具竞争力。
大模型的突破、每 tokens 成本的下降、开源的普及以及芯片性能的提升,正让新技术进步愈发强大、易于获取且在经济上可行。
基于用户、使用情况和商业化指标来看,OpenAI 的 ChatGPT 是史上最大的 “一夜成名” 成功案例(创立九年后)。人工智能在消费者、开发者、企业和政府中的使用量正急剧上升。
而且与互联网 1.0 革命不同 —— 当时技术始于美国,然后稳步向全球扩散 ——ChatGPT 一下子登上世界舞台,在全球大多数地区同步增长。
与此同时,现有主导平台和新兴挑战者都在竞相构建并部署人工智能基础设施的下一层级:智能体界面、企业协同助手、现实世界的自主系统以及主权模型。
人工智能、计算基础设施和全球互联互通的快速发展,正从根本上重塑工作开展方式、资本配置方式以及领导力的定义 —— 涵盖企业和国家层面。
与此同时,全球大国间的领导力也在演变,每个国家都在挑战其他国家的竞争优势和比较优势。我们看到世界上最强大的国家,因不同程度的经济、社会和领土诉求而积极行动起来。
日益凸显的是,两股强大力量 —— 技术力量和地缘政治力量 —— 正相互交织。
安德鲁・博斯沃思(Meta 平台首席技术官)在近期的《Possible》播客中,将当前人工智能的发展状态比作我们的太空竞赛,而我们所谈论的对象,尤其是中国,能力非常强……(在这个领域)几乎没什么秘密可言,只有不断的进步,而且你得确保自己永远不落后。
现实情况是,人工智能领域的领先地位可能会带来地缘政治层面的领先 —— 而非相反。
这种局面带来了极大的不确定性…… 但这又让我们想起一句我们很喜欢的话 —— 从统计学角度讲,世界末日不会经常发生,这话出自普信集团(T. Rowe Price)前董事长兼首席执行官布莱恩・罗杰斯。
作为投资者,我们总会假设一切都可能出问题,但令人兴奋的是去思考哪些方面可能会向好发展。
一次又一次,乐观的理由是人们能做出的最佳选择之一。
看着人工智能为你代劳工作,那种奇妙感觉就像电子邮件和网络搜索刚出现的时候 —— 这些技术从根本上改变了我们的世界。人工智能带来的更优、更快、更省的影响似乎同样神奇,而且速度还要更快。
毫无疑问,当下也是危险且充满不确定性的时期。
但对人工智能持长期乐观态度的依据在于,激烈的竞争与创新…… 日益普及的计算能力…… 全球对融入人工智能技术的快速采纳…… 以及深思熟虑、审慎考量的领导力,能够催生足够的忌惮与尊重,进而可能促成相互确保威慑的局面。
对一些人而言,人工智能的演变会引发一场 “逐底竞赛”;对另一些人来说,它会促成一场 “向顶冲刺”。
资本主义以及创造性破坏带来的投机与狂热力量,具有重大影响力。
不可否认,“竞赛已然开启”,尤其是美国、中国以及那些科技巨头们正奋勇向前。
在这份文件中,我们分享来自第三方的数据、研究和基准指标,这些第三方采用了他们认为有效的方法 —— 我们很感激众多人士付出的努力,在这个独特且充满活力的时期阐释趋势。
我们的目标是为这场讨论添砖加瓦。
1. 看起来变化发生得比以往任何时候都要快吗?是的!

技术复合效应 = 这一发展势头背后的数据
技术复合效应指不同技术相互融合、协同作用,产生远超单一技术简单叠加的效果。如人工智能与大数据、物联网结合,可催生智能医疗、智慧城市等新业态,通过技术间的互补与放大,实现创新突破、效率跃升与复杂问题的系统性解决。
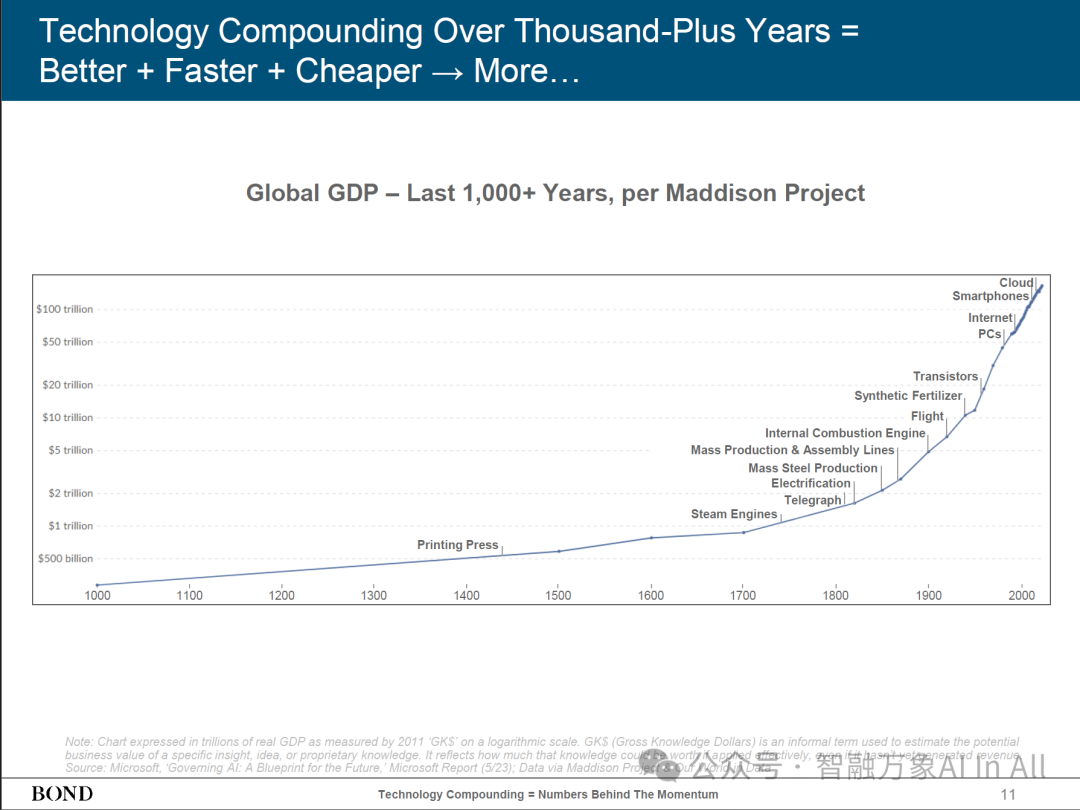
注:图表以 2011 年 “知识美元(GK)衡量的实际国内生产总值万亿为单位,采用对数刻度。知识美元是一个非正式术语,用于估算特定见解、想法或专有知识的潜在商业价值。它反映了如果这些知识得到有效应用,可能具有的价值,即便尚未产生收入。来源:微软,《治理人工智能:未来蓝图》,微软报告(2023 年 5 月);数据源自麦迪逊项目及 “我们的数据世界” 。
以知识价值来衡量GDP的大小,随着技术不断进步和结合,技术的复合效应也在加速,这不仅让人类的生活更快、更好、更便宜(获取相应产品或服务的成本),知识衡量的GDP增长速度越来越快,曲线越来越陡峭。技术的进步也会因此而加速,AI的进步更会加速这一切。
图表反应了自公园1000年依赖,不同历史时期关键技术创新,这些创新与 GDP 增长节点对应,体现技术对经济的推动:
早期(1000 – 1700 年左右 )
印刷术(Printing Press ):约 1400 年前后标注,印刷术传播促进知识传播、文化传承,为后续经济发展和技术创新奠定基础,一定程度上推动经济缓慢增长。
近现代(1700 年之后 )
蒸汽机(Steam Engines ):18 世纪后期,蒸汽机推动工业革命,使生产规模化、机械化,GDP 增长加速,开启经济快速增长阶段。
电气化(Electrification ):19 世纪后期 – 20 世纪初,电力广泛应用改变生产生活方式,工厂生产效率提升,新产业涌现(如电气设备制造 ),进一步拉动 GDP 增长。
大规模钢铁生产(Mass Steel Production )、大规模生产与装配线(Mass Production & Assembly Lines ):20 世纪初,钢铁是工业基础材料,大规模生产降低成本、提高产量;装配线实现标准化、高效生产(如汽车制造 ),大幅提升生产效率,促进经济繁荣。
内燃机(Internal Combustion Engine ):推动汽车、航空等产业发展,改变交通和物流,拓展经济活动范围与效率,助力 GDP 增长。
合成肥料(Synthetic Fertilizer ):20 世纪中期,提高农业产量,保障粮食供应,支撑人口增长和工业发展,对经济基础(农业 )强化作用明显。
晶体管(Transistors ):20 世纪中后期,是电子技术基础,催生计算机、通信等产业,开启信息技术革命,为后续数字经济发展奠基。
这张图清晰展现技术创新是全球 GDP 增长的核心驱动力,从早期印刷术到近现代信息技术,每一次关键技术突破都重塑经济格局、加速增长,反映出技术进步与经济发展相互促进、螺旋上升的关系,也预示未来新的技术创新(如人工智能等 )有望继续推动全球经济迈向新高度 。
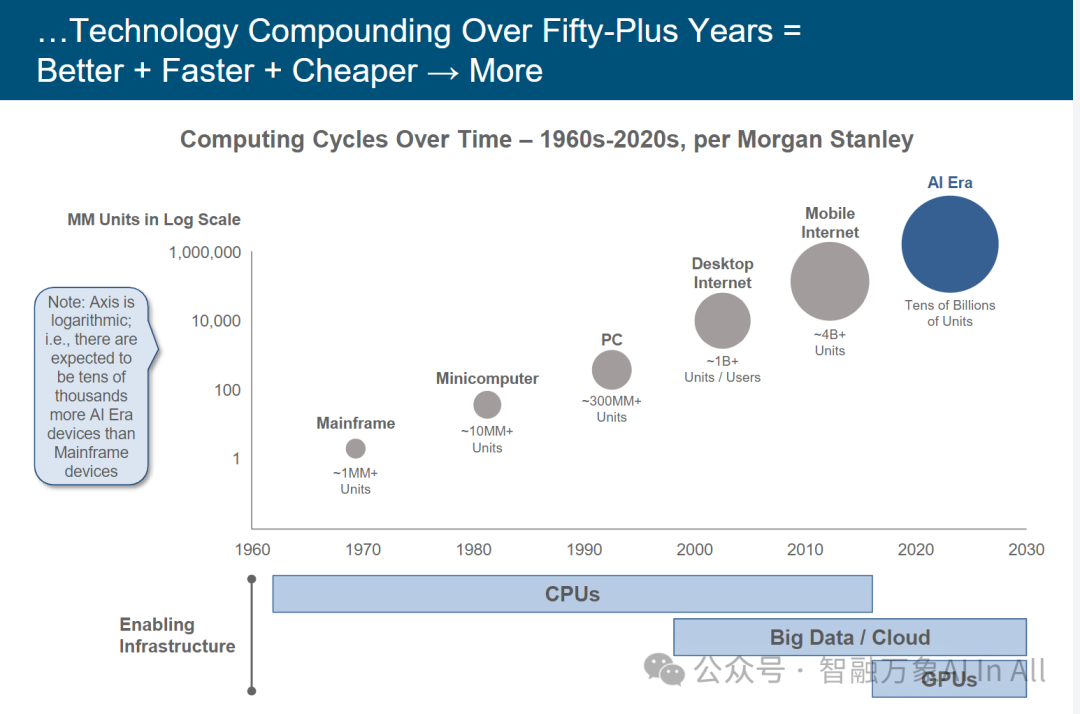
五十余年技术复合效应下的计算周期演进
此图表聚焦 1960 – 2030 年计算周期演变,揭示技术复合作用(Technology Compounding)驱动 “更优、更快、更廉→规模扩张” 的逻辑,核心从三方面解析:
一、计算周期的代际跃迁
大型机(Mainframe,1960 – 1980 年代):代表早期集中式计算,单位规模约 1MM+ ,为企业级核心算力,支撑关键业务系统,奠定计算基础设施雏形。
小型机(Minicomputer,1980 – 1990 年代):规模提升至~10MM+ ,算力分布向部门级渗透,适配企业多元化场景,推动计算应用边界拓展。
个人电脑(PC,1990 – 2000 年代):~300MM+ 单位量,标志计算终端个人化,打破集中式算力垄断,开启大众数字化入口。
桌面互联网(Desktop Internet,2000 – 2010 年代):规模达~1B+ ,网络协同激活 PC 价值,催生 web 应用生态,重塑信息交互与商业形态。
移动互联网(Mobile Internet,2010 – 2020 年代):~4B+ 单位量,移动终端 + 网络深度融合,实现 “随时随地计算”,重构用户行为与产业格局(如移动支付、O2O )。
人工智能时代(AI Era,2020 – 2030 年代):预计达 “Tens of Billions of Units” ,AI 驱动算力需求爆发,终端(如智能设备 )、边缘与云端协同,开启泛在智能新纪元。
二、技术复合的底层逻辑
1. 性能与成本的协同优化:随代际演进,计算单位 “更优(性能迭代,如 AI 时代算力密度飙升 )、更快(响应速度、数据处理效率提升 )、更廉(单位算力成本指数级下降)”,驱动应用规模(More)爆发 —— 符合摩尔定律延伸逻辑,技术进步通过 “降本增效” 突破市场门槛,实现用户与设备量的指数级扩张。
2. 基础设施的迭代支撑
CPU 主导期(1960 – 2000 年代):通用算力基石,支撑传统计算场景(办公、桌面应用 )。
大数据 / 云赋能(2000 年代后):分布式架构 + 海量数据处理,为互联网规模化应用(如社交、电商 )与 AI 训练提供底层支撑。
GPU 崛起(2010 年代后):并行计算架构适配 AI 训练 / 推理需求,成为 AI 时代算力核心引擎,加速技术复合效应。
三、趋势与启示
1. 规模爆发的必然性:对数坐标轴(Log Scale)下,AI 时代设备量较大型机时代 “跃升数个数量级”,反映技术复合积累至临界点后的 “非线性增长”—— 前期技术(如 CPU、网络 )为 AI 奠定基础,AI 反哺推动全场景智能化,形成 “技术 – 需求” 正向循环。
2. 产业变革方向:从 “硬件迭代驱动” 转向 “场景 + 算力 + 算法” 协同,企业需聚焦 “AI 原生应用”(适配海量终端与智能需求 )、“算力基础设施弹性供给”(应对爆发式需求 ),抓住技术复合红利下的新增长极。
简言之,图表以计算周期为锚,展现五十余年技术复合如何通过 “性能 – 成本 – 规模” 螺旋,驱动产业代际跃迁;AI 时代的爆发式增长,既是技术积累的必然,也预示着 “泛在智能” 重塑经济社会的深刻变革。

人工智能技术复合效应 = 发展势头背后的数据
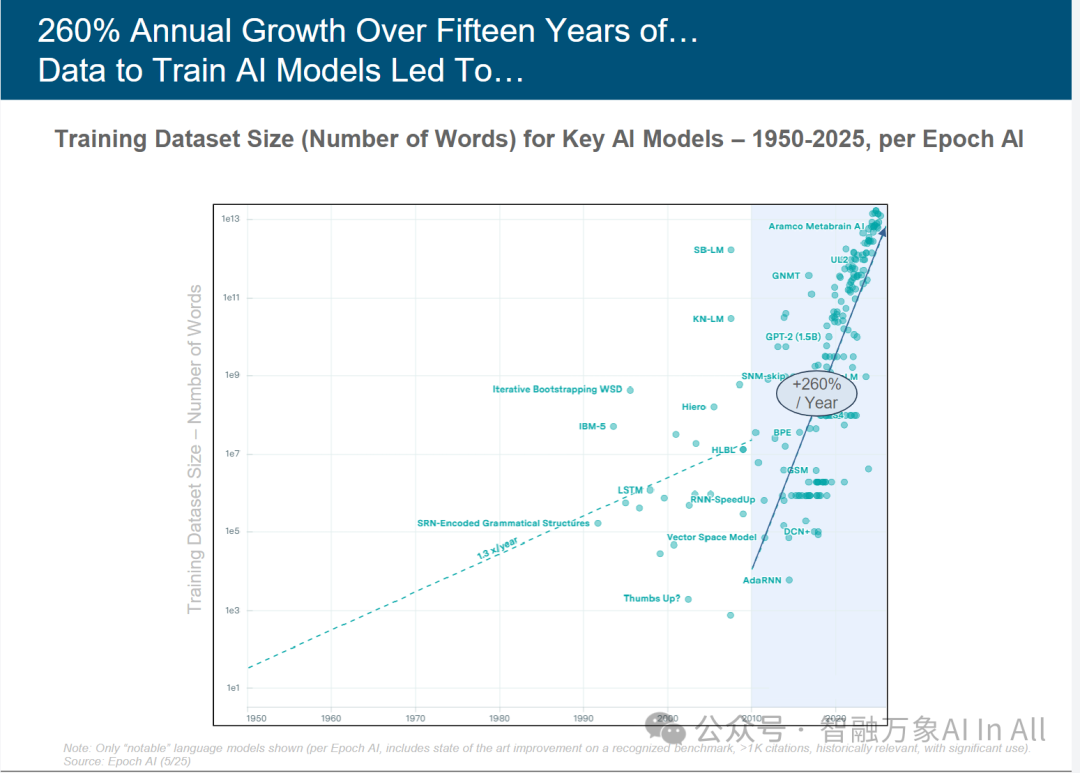
用于训练人工智能模型的数据,过去15年的年化增长是率是260%。
关键人工智能模型训练数据集规模(词数):1950-2025 年发展态势解析
本图表聚焦 1950 – 2025 年关键 AI 模型训练数据集规模(以词数衡量 ),呈现人工智能发展进程中数据驱动的核心规律,从以下维度专业解读:
一、数据规模的时空演进规律
1.长期增长轨迹:纵轴以对数刻度(1e1 到 1e13 )呈现训练数据集词数,横轴为时间(1950 – 2025 年 )。整体呈现指数级增长趋势 —— 早期(1950 – 2000 年 )增速相对平缓(如 “SRN – Encoded Grammatical Structures” 等模型,词数多在 1e5 – 1e9 区间 ),2010 年后进入爆发期,数据规模跨数量级跃升(如 “Aramco Metabrain AI” 等模型逼近 1e13 词数 )。
2. 增速迭代特征:2010 年前,虚线标注 “13 x/year”(年增长 13 倍 ),反映传统自然语言处理(NLP )阶段,数据规模随算法(如 LSTM、Vector Space Model )优化稳步扩张,但受限于数据采集、存储与计算能力,增长幅度有限。
2010 年后,实线标注 “+260% / Year”(年增长 260% ),标志大模型时代降临—— 算力突破(如 GPU 集群 )、开源生态(数据共享与标注 )、商业需求(智能对话、内容生成 )共同驱动,训练数据从 “百万级 / 十亿级” 迈向 “万亿级 / 十万亿级”,数据规模增长呈超线性加速。
二、模型与数据的协同进化
1.早期模型(1950 – 2000 年 ):如 “Thumbs Up?”“Vector Space Model”,数据规模小(多 < 1e7 词 ),适配规则驱动或浅层次机器学习场景(语法结构学习、简单文本分类 ),反映 AI 发展初期 “数据匮乏 – 算法简约” 的约束关系。
2.过渡模型(2000 – 2010 年 ):以 “LSTM”“RNN – SpeedUp” 为代表,数据规模突破 1e9 词,对应深度学习崛起(循环神经网络普及 ),模型开始处理长序列文本(如机器翻译、情感分析 ),数据规模与模型复杂度初步协同升级。
3.大模型时代(2010 年后 ):“GPT – 2 (1.5B)”“Aramco Metabrain AI” 等模型登场,数据规模冲击 1e13 词,体现Transformer 架构+大规模无监督学习的范式革命 —— 模型参数与数据规模 “双膨胀”,通过 “预训练 – 微调” 模式,实现跨领域通用智能(文本生成、逻辑推理 ),数据成为模型能力的核心 “燃料”。
三、产业与技术的底层逻辑
1.算力基建的支撑作用:数据规模爆发依赖计算基础设施迭代 ——2010 年后 GPU 集群、分布式存储普及,突破 “数据存储 – 并行计算” 瓶颈,使万亿级文本训练从 “理论可能” 变为 “工程现实”。
2. 商业需求的反向驱动:智能客服、内容创作、代码生成等商业场景,要求模型具备 “泛化能力” 与 “精准输出”,倒逼企业投入海量数据训练(如科技巨头构建专有数据集 ),形成 “需求 – 数据 – 模型 – 需求” 的闭环强化。
3. 数据治理的潜在挑战:随数据规模扩张,数据质量(噪声、偏差 )、合规性(版权、隐私 )成为关键问题 —— 图表中未体现但隐含风险:若训练数据存在偏差,模型输出可能强化偏见;版权争议也可能制约数据开放与模型迭代。
四、趋势预判与启示
1. 持续爆发的必然性:按 “+260% / Year” 增速,2025 年数据规模将再跨数量级,结合 “摩尔定律” 算力延续与 “数据要素” 市场化,大模型训练将持续向 “更全、更细、更多样” 的数据池演进。
2. 产业分化的可能性:头部企业(掌握海量数据与算力 )将强化 “数据壁垒”,中小厂商依赖开源数据与轻量化模型,行业或呈现 “头部集中 + 长尾创新” 格局。
3. 技术突破的新方向:为缓解 “数据饥渴”,未来可能涌现高效数据利用技术(如数据蒸馏、小样本学习 ),或探索 “合成数据生成”,降低对真实数据规模的依赖。
综上,该图表揭示人工智能发展的 “数据驱动本质”:从早期受限于数据,到如今数据规模定义模型能力边界,2010 年后的爆发不仅是技术量变,更是 AI 范式从 “弱智能” 到 “通用智能” 的质变标志。理解数据规模的演进规律,对布局 AI 研发、产业应用与风险治理,均具核心参考价值。
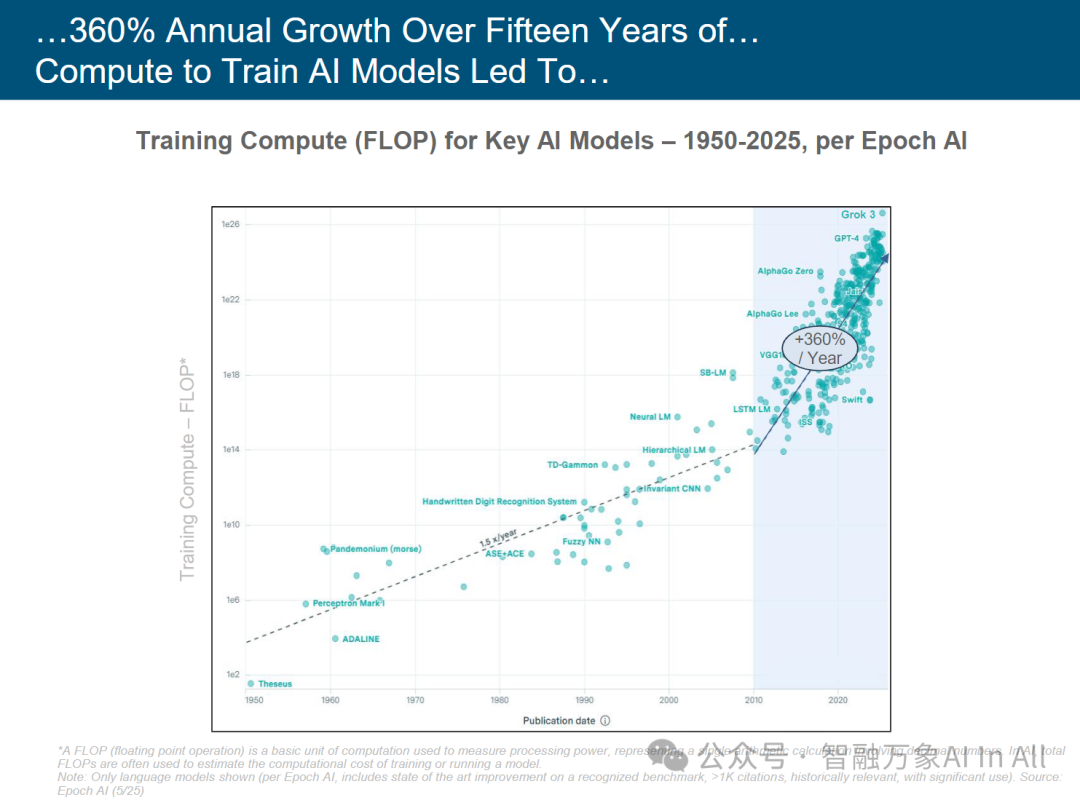
过去15年,用于大模型的算力年化增长是率是360%。
关键 AI 模型训练算力(FLOP)发展(1950 – 2025)
这张图表由 Epoch AI 制作,呈现 1950 – 2025 年关键 AI 模型训练算力(以 FLOP 衡量 )的变化。核心要点如下:
1. 算力增长趋势
纵轴为训练算力(对数刻度,从 1e2 到 1e26 FLOP ),横轴是模型发布时间。
整体呈指数级增长,早期(1950 – 2000 年 )增速较缓(如 “ADALINE”“Perceptron Mark I” 等模型,算力多在 1e6 – 1e14 FLOP );
2010 年后进入爆发期,以 “GPT – 4”“Grok 3” 为代表的大模型,算力逼近 1e26 FLOP ,体现 “+360% / Year” 的年增速,反映 AI 训练对算力需求的急剧攀升。
2. 技术代际演进
早期模型(1950 – 2000 年 ):如 “Handwritten Digit Recognition System”,适配简单任务(手写识别 ),算力需求低,依赖基础算法与硬件。
过渡模型(2000 – 2010 年 ):“LSTM LM”“Neural LM” 等模型,随深度学习(如 LSTM )普及,算力需求突破 1e14 FLOP ,开启算法与算力协同升级。
大模型时代(2010 年后 ):“AlphaGo Zero”“GPT – 4” 等登场,Transformer 架构 + 大规模训练,算力需求呈超线性增长,凸显 “算力即生产力” 的 AI 研发逻辑。
3. 产业与技术逻辑
算力爆发依赖硬件迭代(GPU/TPU 集群 )、算法优化(分布式训练 )与商业驱动(通用 AI 需求 )。头部企业(如 OpenAI、Google )凭借算力资源构建 “技术壁垒”,同时也隐含 “算力成本高企”“能源消耗” 等挑战。
综上,图表揭示 AI 发展的“算力驱动本质”:从早期受限于硬件,到如今算力规模定义模型能力边界,2010 年后的爆发标志 AI 从 “实验性” 迈向 “工业化” 训练阶段,理解算力演进对布局 AI 研发与产业竞争具关键价值。
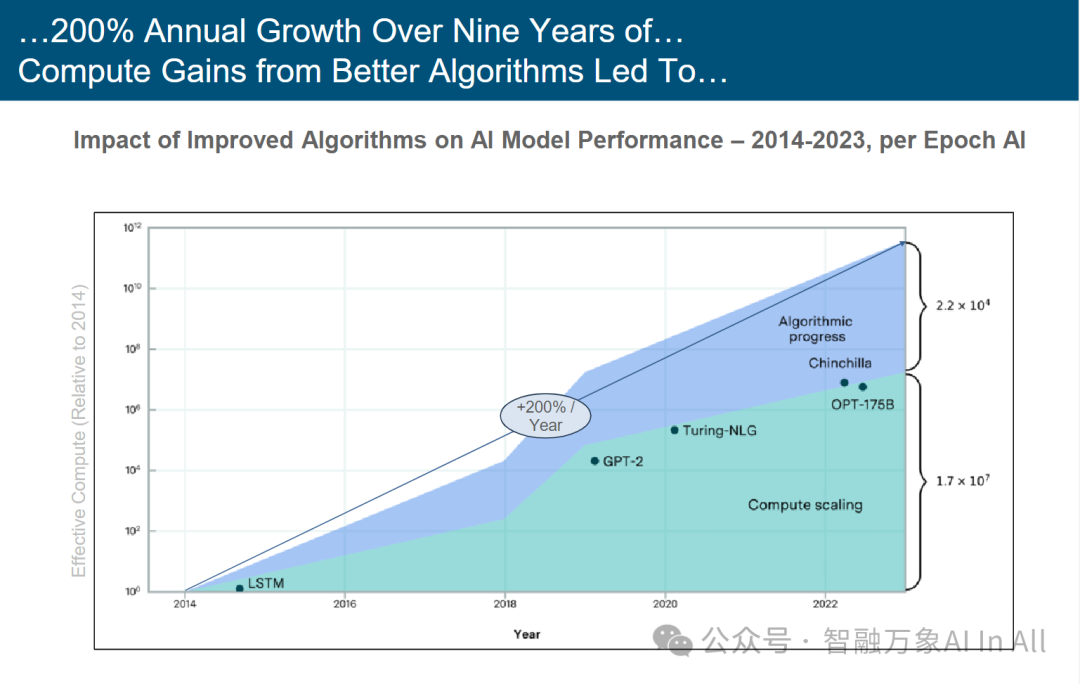
源自更优算法的计算效能提升,九年期间年增长率达 200%
算法优化驱动算力增益对 AI 模型性能的影响(2014-2023)
本图聚焦 2014-2023 年算法改进对 AI 模型有效算力及性能的作用,从专业视角解析:
一、核心趋势:算力增益的双引擎驱动
图表以 “相对 2014 年的有效算力(Effective Compute)” 为纵轴(对数刻度 )、时间为横轴,呈现 算法进步(Algorithmic progress)与算力扩容(Compute scaling)共同驱动的增长:
1. 算法进步(蓝色区域):2014-2023 年,算法优化使单位算力产出的模型效能提升,年增速达 **+200%** 。典型如 “Chinchilla” 等模型,通过架构创新(如更高效的训练策略、模型压缩 ),用更少算力实现更优性能。
2. 算力扩容(青色区域):硬件迭代(如 GPU 集群 )与分布式训练普及,直接扩大算力供给,支撑 “OPT-175B” 等超大规模模型训练,体现 “算力堆量” 的直接贡献。
二、模型代际演进与算力效率
早期模型(2014-2018 年 ):以 “LSTM”“GPT-2” 为代表,依赖基础算法,有效算力增长平缓,反映传统架构对算力的低效利用。
进阶模型(2018-2023 年 ):“Turing-NLG”“Chinchilla” 等登场,算法突破(如 Transformer 优化、数据高效训练 )使有效算力 “非线性跃升”——在算法进步驱动下,小算力投入可实现大模型性能突破,标志 “算力效率革命”。
三、产业与技术逻辑
1. 算法的核心价值:算法进步打破 “算力依赖” 瓶颈,证明模型性能提升不仅靠 “堆硬件”,更需算法创新(如稀疏化、自监督学习 ),为中小厂商降低 AI 研发门槛。
2. 双引擎协同效应:算法优化与算力扩容形成 “正反馈”—— 高效算法适配大算力,释放更大模型潜力(如 GPT 系列 );大模型反哺算法迭代(如强化学习优化 ),推动 AI 性能持续突破。
3. 能效挑战与机遇:随算力需求飙升,“算法提效” 成为缓解能源消耗、成本压力的关键,催生 “绿色 AI” 研究(如低功耗算法、算力调度优化 )。
四、趋势启示
1. 研发范式转变:从 “纯算力驱动” 转向 “算法 + 算力” 协同,企业需平衡硬件投入与算法创新,构建差异化竞争力。
2.长尾创新空间:算法进步降低算力门槛,为垂直领域(医疗、工业 )AI 应用提供 “小数据 + 高效算法” 的发展路径。
3. 性能边界拓展:双引擎驱动下,AI 模型性能将持续突破,预计未来 “算法提效” 对有效算力的贡献占比进一步提升,重塑行业技术路线。
简言之,图表揭示 AI 发展的 “算法红利”:200% 年增速的算法进步,与算力扩容协同,重塑模型性能增长曲线;理解这一双引擎逻辑,是布局 AI 研发、平衡成本与创新的核心支点。
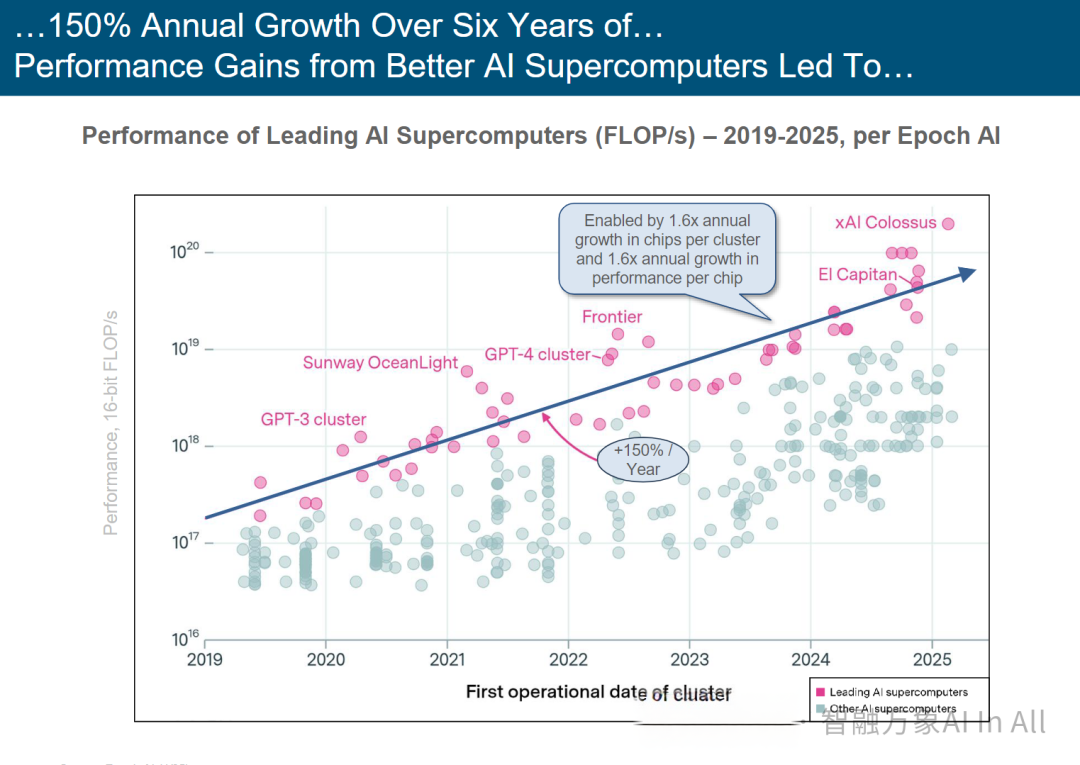
人工智能超级计算机带来的性能提升,过去6年增长了150%。
顶尖人工智能超级计算机性能(2019-2025)
本图表聚焦 2019-2025 年顶尖 AI 超级计算机性能(以 16 位浮点运算每秒,即 16-bit FLOP/s 衡量 ),核心解析如下:
一、性能增长核心逻辑
图表以 “集群首次运行时间” 为横轴、“性能(16-bit FLOP/s )” 为纵轴(对数刻度 ),呈现三重增长驱动:
1. 年增长率 150%:整体性能呈指数级上升,年增速达 150% ,反映 AI 超级计算机集群算力的快速迭代。
2.芯片与集群协同:性能提升由 “每集群芯片数量年增 1.6 倍”+“单芯片性能年增 1.6 倍” 共同驱动,通过 “硬件规模扩容” 与 “单芯片效能优化”,实现集群算力的复合式增长。
二、集群性能代际演进
1. 早期集群(2019-2021 年 ):以 “GPT-3 cluster”“Sunway OceanLight” 为代表,性能多在 10¹⁷ – 10¹⁹ FLOP/s 区间,依赖基础硬件架构,体现 AI 算力初步规模化。
2. 进阶集群(2022-2024 年 ):“Frontier”“GPT-4 cluster” 等登场,性能突破 10¹⁹ FLOP/s ,标志 “芯片 + 集群” 协同优化见效,支撑大模型(如 GPT-4 )训练等高算力需求任务。
3. 前沿集群(2024-2025 年 ):“xAI Colossus”“El Capitan” 等,性能逼近 10²⁰ FLOP/s ,凸显顶尖玩家在硬件堆叠(更多高性能芯片 )与架构创新(更高效集群调度 )上的突破,为下一代 AI 研发(如 AGI 探索 )奠基。
三、产业与技术启示
1. 硬件迭代的战略价值:AI 超级计算机性能增长,本质是 “芯片技术(制程、架构 )” 与 “集群工程(互联、调度 )” 的协同竞赛,头部企业(如 xAI、超算中心 )通过掌控硬件迭代节奏,构建算力壁垒。
2.大模型发展的支撑逻辑:GPT 系列集群性能与模型迭代强关联(GPT-3→GPT-4 算力跃升 ),证明超级计算机性能是大模型 “参数规模、训练效率” 的核心支撑,算力即模型生产力。
3. 未来挑战与机遇:随性能增长,能耗、成本、硬件适配性(如 AI 芯片专用化 )成为瓶颈;但也催生 “异构计算”“存算一体” 等技术创新,推动超算向更高效、更适配 AI 需求演进。
四、趋势预判
1. 性能持续爆发:按 150% 年增速与芯片 – 集群协同逻辑,2025 年顶尖集群性能将再跨数量级,进一步拉开头部与尾部玩家的算力差距。
2. 应用边界拓展:超算性能突破将赋能更复杂 AI 任务(如长序列推理、多模态融合 ),加速 AI 从 “模型训练” 到 “产业落地” 的转化。
3. 技术路线分化:一方面,通用超算追求极致性能;另一方面,专用 AI 超算聚焦能效比与场景适配,形成 “通用 + 专用” 双轨发展。
简言之,图表揭示 AI 超级计算机的 “性能增长密码”:芯片与集群的双重迭代,驱动算力年增 150% ,支撑大模型与 AI 产业突破;理解这一逻辑,是布局 AI 硬件研发、模型训练与产业竞争的关键支点。
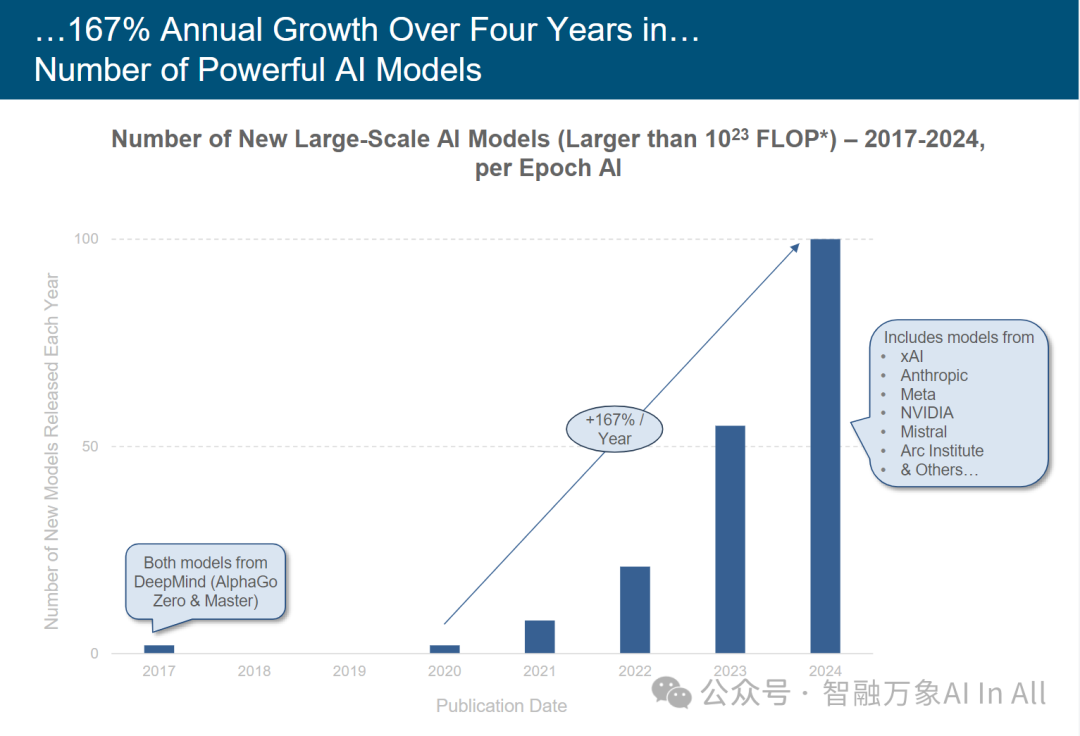
四年期间,人工智能大规模模型数量实现 167% 的年增长率
大规模 AI 模型数量增长(2017 – 2024)
该图表聚焦 2017 – 2024 年新大规模 AI 模型(计算量超 10²³ FLOP )数量的发展趋势,核心解读如下:
一、核心增长态势
图表以 “发布年份(Publication Date)” 为横轴、“年度新模型数量(Number of New Models Released Each Year)” 为纵轴,呈现爆发式增长:
2017 年仅 DeepMind 的 2 个模型(AlphaGo Zero & Master );2024 年新模型数量逼近 100 ,年增长率达 167% ,反映大规模 AI 模型研发进入 “指数扩张期”。
二、驱动因素与产业格局
1.技术与算力突破:模型训练算力需求(超 10²³ FLOP )的满足,依赖硬件迭代(如 GPU 集群性能提升 )与算法优化(降低算力消耗 ),使更多机构具备研发条件。
2020 年后增长加速,与 “Transformer 架构普及”“开源生态成熟”“云计算算力开放” 直接相关。
2. 参与主体多元化:早期(2017)仅 DeepMind 主导;2024 年涵盖 xAI、Anthropic、Meta、NVIDIA 等科技巨头,及 Mistral、Arc Institute 等新兴力量,体现 “头部 + 长尾” 协同创新—— 巨头凭算力 / 数据优势推旗舰模型,新兴机构聚焦垂直领域或轻量化大模型。
三、趋势启示与挑战
1. 创新生态繁荣:模型数量爆发预示 AI 研发从 “稀缺化” 转向 “普惠化”,更多行业(医疗、工业 )将受益于定制化大模型,加速 AI 落地。
2. 质量与同质化隐忧:数量增长伴随 “模型冗余” 风险—— 部分模型仅为 “参数竞赛”,缺乏实质创新;需关注 “模型效果验证”“场景适配度”,避免资源浪费。
3.治理需求升级:大规模模型增多,对伦理(偏见、安全 )、合规(数据版权、隐私 )、监管(风险评估、应用限制 )提出更高要求,需构建跨领域治理框架。
四、未来展望
1. 持续增长惯性:按 167% 年增速与算力 / 算法发展趋势,2025 年后新模型数量或继续攀升,推动 AI 能力边界拓展。
2. 分化与聚焦:头部企业聚焦 “通用大模型 + 超级应用”,新兴机构深耕 “垂直领域 + 细分场景”,形成差异化竞争。
3. 协同与治理:跨机构合作(如开源联盟 )与全球化治理(如模型安全标准 )将成关键,平衡创新与风险。
简言之,图表揭示大规模 AI 模型从 “单点突破” 到 “全面爆发” 的演进,数量增长是技术、产业与资本协同的结果,也预示 AI 将进入 “百花齐放但需有序引导” 的新阶段 —— 理解这一趋势,对布局研发、产业应用与风险管控具核心价值。
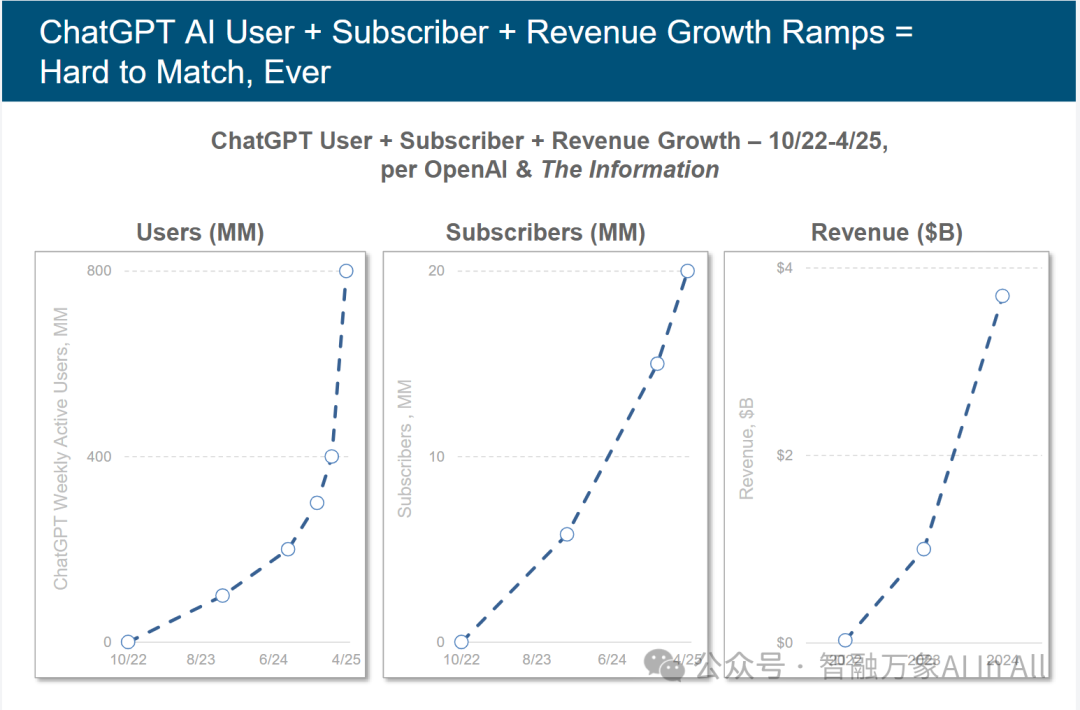
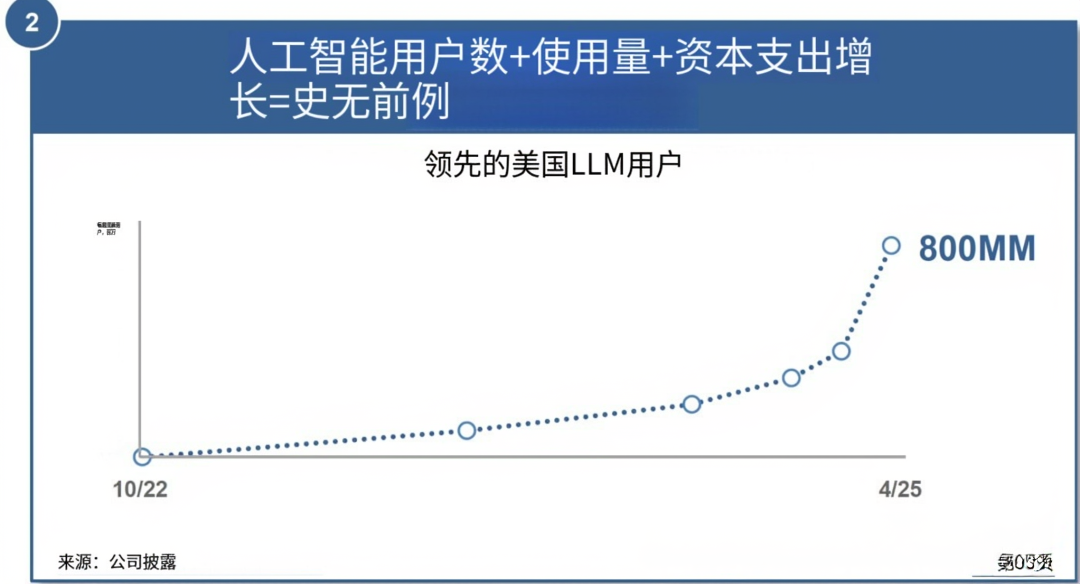
ChatGPT 人工智能的用户、订阅用户及收入增长曲线 —— 难以企及,空前绝后
该图表呈现 ChatGPT 在 2022 年 10 月 – 2025 年 4 月期间,用户(Users)、订阅者(Subscribers)、收入(Revenue)的增长曲线,其爆发式增长对 AI 领域发展具多重深远意义:
一、市场验证与生态
1. 激活用户侧:周活跃用户超 8 亿(预计 2025 年 4 月 ),印证通用 AI 应用的市场刚需—— 打破 “AI 技术曲高和寡” 困境,证明大模型可深度渗透 C 端日常场景(对话、创作、学习 ),激活全民对 AI 工具的认知与使用习惯,为行业培育海量用户基数。
2. 商业侧:订阅用户与收入同步飙升,验证AI 商业化路径的可行性—— 通过 “免费 + 付费订阅” 模式,实现用户留存与商业变现,为 AI 企业提供 “技术 – 市场 – 收入” 闭环参考,驱动资本与资源向 AI 应用层倾斜。
二、技术迭代与竞争格局
1.技术倒逼:用户规模与需求增长,倒逼模型迭代加速(如功能优化、多模态融合 ),推动大模型从 “能用” 向 “好用” 进化;同时,高并发使用场景暴露的性能、安全问题,也驱动算力基建(如集群优化 )与算法创新(如推理加速 )。
2.竞争激化:ChatGPT 的增长标杆,引发行业军备竞赛—— 科技巨头(微软、谷歌 )加大 AI 投入,新兴玩家加速追赶,推动技术突破与生态分化(通用大模型、垂直领域模型并存 ),重塑 AI 产业竞争格局。
三、产业融合与社会影响
1. 产业渗透:用户与收入增长反映 AI 从 “技术概念” 向 “产业基建” 转变,驱动千行百业 AI 化—— 教育、医疗、办公等领域借大模型实现效率升级,催生 “AI+” 新业态(如智能客服、内容生成平台 ),重构传统产业流程。
2. 社会重塑:全民 AI 使用习惯养成,将引发社会生产关系变革—— 工作模式(人机协同常态化 )、教育方式(个性化 AI 辅助学习 )、创作生态(AI 参与内容生产 )被重塑,推动社会向 “智能协作时代” 演进。
四、挑战与反思
1.伦理风险:用户规模扩张伴随数据隐私、算法偏见等问题,需建立更完善的治理框架,平衡创新与安全。
2. 可持续性:爆发式增长后,需验证用户留存与需求深度—— 避免 “尝鲜式使用”,确保 AI 价值持续输出,支撑长期商业闭环。
综上,ChatGPT 的增长不仅是单一产品的成功,更是 AI 领域 “技术 – 市场 – 社会” 协同突破的标志:它验证了大模型的商业潜力,激化技术竞争,加速产业融合,也倒逼行业直面伦理与可持续性挑战。这一趋势预示 AI 将从 “技术驱动” 全面转向 “生态驱动、社会协同” 的发展新阶段,深刻重塑科技与社会形态。
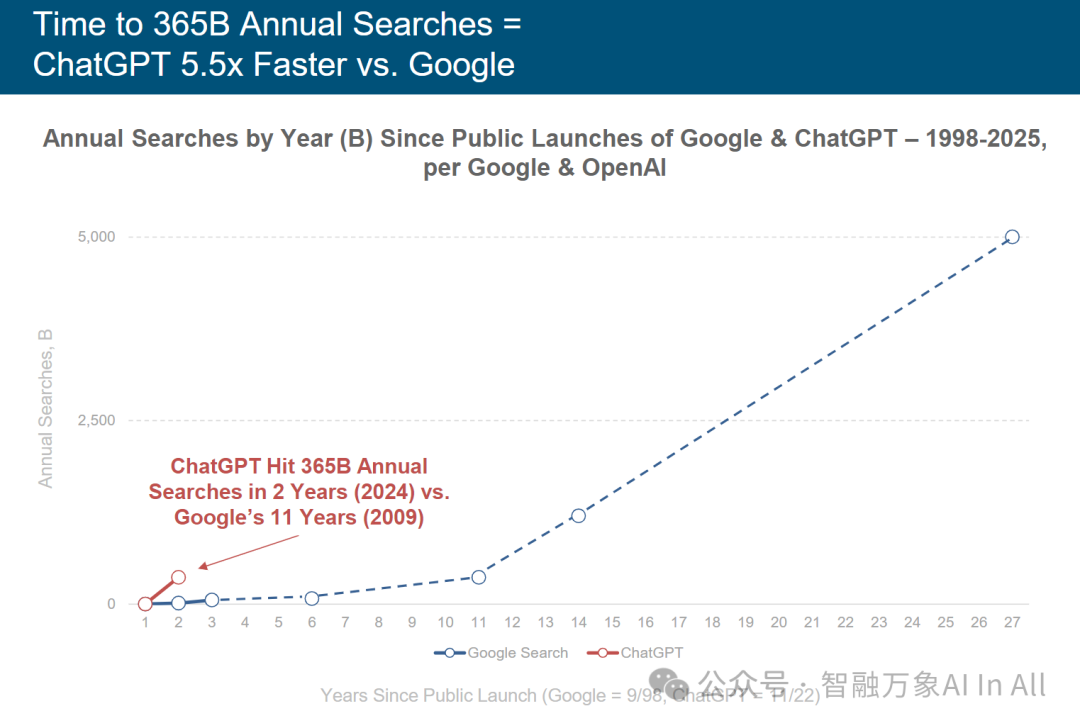
达到 3650 亿次年度搜索量的时间 ——ChatGPT 比 Google 快 5.5 倍
ChatGPT 与 Google 搜索年度搜索量增长对比(1998 – 2025)
本图表聚焦 Google 搜索与 ChatGPT 自公开推出后,年度搜索量(单位:十亿次,B)的增长周期对比,核心解读如下:
一、核心结论:增长速度的代际差异
图表标题 “达到 3650 亿次年度搜索量的时间 ——ChatGPT 比 Google 快 5.5 倍”,通过数据呈现AI 交互模式对传统搜索的颠覆:
1.Google 搜索(1998 年公开推出 ):耗时11 年(至 2009 年 )达到 3650 亿次年度搜索量。
2.ChatGPT(2022 年 11 月公开推出 ):仅用2 年(至 2024 年 )即达到同等规模,增长速度差距显著(5.5 倍 )。
二、增长曲线的阶段特征
1. Google 搜索(蓝色曲线)
早期(推出后 1-5 年 ):增长平缓,反映互联网普及初期的用户教育与市场渗透过程。
中期(5-15 年 ):进入指数增长期,伴随互联网红利(PC 普及、网页数量爆发 ),搜索量快速攀升。
后期(15 年以上 ):增速趋稳,逐渐逼近市场饱和(用户搜索习惯固化、流量分散至社交 / 短视频等平台 )。
2. ChatGPT(红色曲线)
推出即进入陡峭增长期:依托大模型的自然语言交互优势,快速捕获用户需求(对话式搜索、内容生成 ),跳过 “用户教育期”,直接进入爆发增长。
短期突破传统搜索十年周期:体现AI 原生应用的竞争力—— 更高效的信息触达、更贴近用户需求的交互形式,重构搜索市场的增长逻辑。
三、产业与技术启示
1. 交互范式革命:ChatGPT 的增长印证 “对话式 AI” 对 “关键词搜索” 的替代潜力,自然语言理解(NLU)技术突破使信息获取更直接、高效,推动搜索从 “工具” 向 “智能助手” 进化。
2.市场竞争格局:传统搜索巨头(Google )面临AI 原生玩家(OpenAI + 微软 )的直接冲击,需加速大模型融合(如 Bard )以应对用户迁移;同时,ChatGPT 的成功也激活 “AI + 搜索” 赛道,催生更多创新玩家。
3. 增长驱动力差异:
Google 依赖互联网生态扩张(网页、用户、设备增长 );
ChatGPT 依托技术创新红利(大模型性能、交互体验 )与需求升级(用户对智能服务的渴求 ),揭示 AI 时代 “技术突破直接驱动增长” 的新规律。
四、未来趋势预判
1.搜索市场分化:对话式 AI 搜索与传统关键词搜索将形成 “智能交互 + 精准检索” 双轨 ,满足不同用户需求(如深度问答 vs 信息定位 )。
2.增长持续力挑战:ChatGPT 需验证用户需求的可持续性—— 避免 “尝鲜式使用”,通过功能迭代(多模态、个性化 )与生态构建(插件、企业应用 ),维持增长曲线陡峭度。
3. 技术军备竞赛:搜索量竞争背后是大模型算力、数据、算法的比拼,企业需持续投入技术研发,巩固增长优势。
简言之,图表揭示 AI 时代 “技术创新驱动增长” 的颠覆力:ChatGPT 以 5.5 倍于 Google 的速度突破搜索量里程碑,不仅是产品成功,更是 “对话式 AI” 重构搜索产业的标志。这一趋势预示搜索市场将进入 “智能交互主导” 的新阶段,传统与新兴玩家需重新定义竞争规则。

1998 年,借助新兴的互联网接入方式,谷歌着手开展工作,目标是 “整理全球信息,使其能被广泛获取并发挥效用” 。
近三十年之后 —— 在经历了人类有史以来最为迅猛的变革之一后 —— 大量信息的确实现了数字化、可获取性以及实用性。
由人工智能驱动的、关于我们获取和传递信息方式的演变,正以快得多的速度发生……
……人工智能是一个助推因素,作用于互联网基础设施,助力易于使用、具有广泛吸引力的服务以极快的速度被采用。
超详细解读第1部分
第2部分开始:

跨越6个世纪的知识传播革命

1440年,发明了印刷出版,从1440-1992年,知识的传播都是静态和物理实体传递的。
1993年,互联网对公众开放,从1993-2021年,知识的传播是动态和数字化传递的。

2022年,AI的大语言模型突破,2022年后,知识的传播在动态、数字化的基础上,增加了生成式的传递。

知识是积累事实的过程;
智慧在于对事实的简化。
—— 马丁・H・费舍尔(德裔美国内科医生 / 教师 / 作家,1879 – 1962 年)

AI:起飞前的很多年
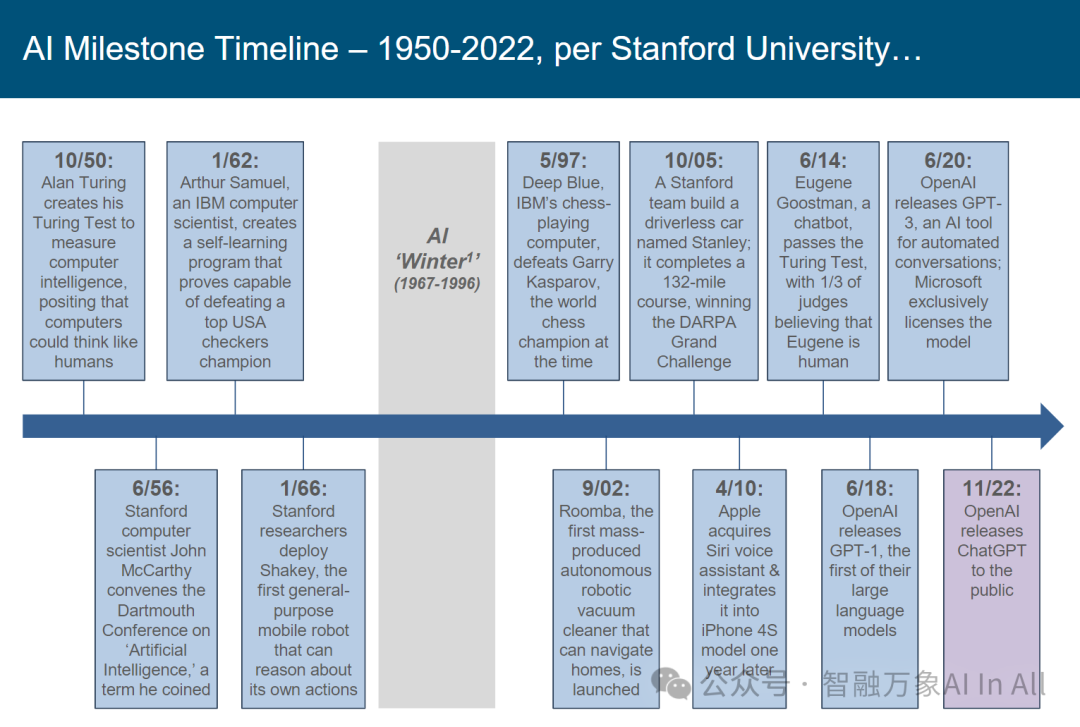
斯坦福大学版人工智能里程碑时间线(1950-2022)
本时间线由斯坦福大学梳理,呈现 1950-2022 年人工智能(AI)发展关键节点,从技术演进、产业影响与周期波动视角专业解析:
一、萌芽与奠基期(1950-1967)
1. 图灵测试(1950.10):阿兰・图灵提出 “图灵测试”,定义 “机器能否像人类一样思考” 的判定框架,为 AI 确立哲学与理论基石,奠定 “智能模拟” 的研究方向。
2. 达特茅斯会议(1956.6):约翰・麦卡锡召集达特茅斯会议,首次提出 “人工智能(Artificial Intelligence)” 术语,标志 AI 成为独立学科,启动学术研究浪潮。
3. 自学习程序(1962.1):阿瑟・塞缪尔开发自学习跳棋程序,证明机器可通过经验迭代优化,实现特定任务(跳棋 )超越人类冠军,验证 “机器学习” 可行性。
4. 通用移动机器人(1966.1):斯坦福推出 Shakey 机器人,可自主推理行动,探索通用智能体(General AI )雏形,虽受限于硬件,却拓展 AI 应用边界。
二、第一次 “AI 寒冬”(1967-1996)
1967-1996 年为 “AI Winter”,因早期乐观预期(如通用智能短期实现 )与技术现实(算力、数据匮乏 )落差,导致资金与关注骤减。此阶段 AI 从 “学术狂热” 回归冷静,倒逼基础技术(算法、硬件 )沉淀。
三、复苏与突破期(1996-2022)
(一)专用智能突破
1.深蓝击败人类(1997.5):IBM “深蓝” 击败国际象棋冠军卡斯帕罗夫,证明专用领域(棋类 )AI 可超越人类,标志算力与算法协同突破 “复杂规则任务”。
2.Roomba 机器人(2002.9):首款量产自主扫地机器人 Roomba 上市,推动 AI 从 “实验室” 走向消费级应用,验证 “环境感知 + 自主决策” 的商业化潜力。
3.无人驾驶夺冠(2005.10):斯坦福 “Stanley” 无人车完成 132 英里越野赛,展示 AI 在动态环境决策(路况、障碍 )的能力,加速自动驾驶技术落地。
4.Siri 集成 iPhone(2010.4):苹果收购 Siri 并集成至 iPhone 4S,使语音交互 AI进入十亿级用户市场,开启 “移动 AI 普及潮”。
(二)大模型与通用智能逼近
1. GPT-1 发布(2018.6):OpenAI 推出 GPT-1,开启大语言模型(LLM ) 时代,通过 “预训练 + 微调” 实现跨领域文本处理,重塑自然语言理解范式。
2. 图灵测试 “通关”(2014.6):聊天机器人 Eugene Goostman 通过图灵测试(1/3 评委认为其为人类 ),虽存争议,但标志 AI 在对话智能上的显著进步。
3. GPT-3 与 ChatGPT(2020.6;2022.11):GPT-3 以超大参数规模实现 “少样本学习”,ChatGPT 则通过交互优化引爆 C 端需求,推动 AI 从 “工具” 向智能助手进化,重塑信息交互、内容生产模式。
四、产业与技术逻辑
1. 周期波动规律:“AI 寒冬” 是技术泡沫的理性修正,后续复苏依赖 ** 算力(如 GPU )、数据(互联网红利 )、算法(Transformer )** 的协同突破,印证技术创新的 “螺旋上升” 特征。
2. 应用扩散路径:从 “专用领域(棋类、工业 )” 到 “消费级应用(Roomba、Siri )”,再到 “通用智能探索(GPT 系列 )”,体现 AI 从 “垂直场景” 向 “泛在智能” 的渗透,驱动产业智能化升级。
3. 生态权力转移:早期由学术机构(斯坦福、达特茅斯 )主导,中期科技巨头(IBM、苹果 )推动商业化,近年 OpenAI 等新锐企业借大模型重塑格局,反映创新主体的动态演变。
五、趋势启示
1. 技术普惠化:ChatGPT 等应用使 AI 从 “专业工具” 变为 “大众服务”,预计未来 “AI 平民化” 将加速,催生更多长尾应用。
2. 伦理与治理需求:大模型普及伴生 “偏见、虚假信息、就业冲击” 等问题,需构建跨领域治理框架(如算法审计、伦理准则 )。
3. 持续突破方向:通用人工智能(AGI )仍是长期目标,需突破 “上下文局限、多模态融合、因果推理” 等技术瓶颈,推动 AI 从 “弱智能” 向 “强智能” 演进。
简言之,该时间线勾勒 AI 从 “概念诞生” 到 “全民应用” 的七十年历程:既有寒冬期的理性沉淀,也有突破期的爆发创新。理解这一演进,对把握 AI 技术趋势、产业机遇与社会影响,具核心参考价值。

斯坦福大学版 2023-2025 年 AI 里程碑时间线
本时间线聚焦 2023-2025 年人工智能(AI)发展关键动态,从技术演进、产业竞争与生态治理维度专业解析:
一、技术突破与模型迭代
(一)多模态与大模型升级
1.GPT-4(2023.3):OpenAI 发布多模态模型,支持文本 + 图像处理,推动 AI 从 “单一模态” 向 “多模态融合” 进化,拓展内容生成、视觉理解等应用场景。
2. GPT-4.5/Grok 3(2025.2):OpenAI、xAI 持续迭代大模型,反映参数规模与泛化能力的竞赛,追求更高效的语言理解、推理与交互体验。
3. Qwen 2.5/Max(2024.9;2025.1):阿里云开源及升级大模型,在推理性能上对标国际头部(GPT-4o、Claude 3.5 ),体现开源生态与闭源竞争的平衡。
(二)垂直领域模型深耕
1. DeepSeek R1(2025.1):聚焦 “推理模型”,针对逻辑推理、复杂任务优化,满足 垂直场景(科研、金融 )对精准智能的需求。
2. Apple Intelligence(2024.7):苹果集成 AI 系统至设备,强化 “端侧智能”,推动 AI 从 “云端集中” 向 “端云协同” 演进,保障隐私与实时交互。
二、产业竞争与生态布局
(一)巨头博弈:技术与市场争夺
1. 谷歌 Bard(2023.3):对标 ChatGPT 推出对话模型,回应 OpenAI 冲击,巩固搜索 + AI 生态;
2. Meta Llama 3(2024.4):开源 70B 参数模型,以 “开放生态” 争夺开发者与企业客户,削弱闭源模型壁垒;
3. 微软 Copilot(2023.3):集成至 Office 365,将大模型能力嵌入办公场景,实现“AI + 生产力工具”深度融合,重构职场效率。
(二)全球化与合规竞速
1. Bletchley Declaration(2023.11):28 国(含中美欧 )签署 AI 安全声明,启动全球治理框架构建,应对风险(偏见、失控 )与竞争;
2. 美国国土安全部 AI 战略(2024.3):政府部门发布路线图,推动 AI 在安全、公共服务中的应用,体现政策引导与技术落地的协同。
三、用户与商业落地
1. ChatGPT 用户突破 8 亿(2025.4):周活用户达 8 亿,印证 C 端 AI 应用的全民渗透,反映对话式 AI 成为信息交互、服务获取的主流入口;
2. Claude 聚焦安全(2023.3):Anthropic 推出 “安全 + 可解释”AI 助手,回应伦理关切,探索“可信 AI”商业化路径。
四、趋势与启示
1. 技术路径分化:大模型向 “多模态(GPT-4 )”“端侧智能(Apple )”“垂直推理(DeepSeek )” 分化,满足不同场景需求,避免单一技术路线垄断。
2. 生态竞合格局:开源(Meta Llama )与闭源(OpenAI )、国际巨头(谷歌、微软 )与本土玩家(阿里云、DeepSeek )共存,推动技术迭代与市场覆盖。
3. 治理前置化:Bletchley Declaration 等行动,标志 AI 治理从 “事后监管” 转向 “事前协同”,平衡创新与风险成为全球共识。
简言之,2023-2025 年 AI 发展呈现 “技术深耕、生态混战、治理协同” 特征:大模型持续突破边界,产业竞争从 “模型发布” 升级为 “生态构建”,且全球化治理加速介入。理解这一阶段,对把握 AI 商业化机遇、技术投资方向与伦理风险管控,具核心参考价值。

AI:大约25年Q2
ChatGPT认为,今天AI能做的10类事情
1. 撰写或编辑任何内容:电子邮件、文章、合同、诗歌、代码 —— 瞬间流畅完成。
2. 总结并阐释复杂材料:将 PDF、法律文件、研究资料或代码简化为通俗易懂的英语。
3. 几乎在任何学科上为你辅导:逐步学习数学、历史、语言,或备考。
4. 成为你的思考伙伴:头脑风暴创意、调试逻辑,或检验假设。
5. 自动完成重复性工作:生成报告、清理数据、拟定幻灯片大纲、重写文本。
6. 扮演你需要的任何角色:为面试做准备、模拟客户、演练对话。
7.帮你衔接各类工具:为应用程序接口(APIs)、电子表格、日历或网页编写代码。
8. 提供心理疏导与陪伴:聊聊你的日常、重塑思维,或单纯倾听。
9. 助力你找到人生目标:明晰价值观、界定目标,规划有意义的行动。
10. 规划你的生活:规划旅行、建立日常惯例、安排每周事务或工作流程。

AI:大约2030年
ChatGPT认为,未来5年AI最可能做到的10类事情
1. 生成人类水平的文本、代码与逻辑:聊天机器人、软件工程、商业计划、法律分析。
2. 创作长篇电影与游戏:剧本、角色、场景、游戏机制、配音。
3. 像人类一样理解与交流:具情感感知的助手、实时多语言语音代理。
4. 助力先进的个人助手:人生规划、记忆唤起、跨应用及设备的协调。
5. 操控类人机器人:家庭助手、老年护理、零售及酒店业自动化。
6. 自主开展客户服务与销售:端到端问题解决、追加销售、客户关系管理系统集成、7×24 小时支持。
7. 个性化整个数字生活:自适应学习、动态内容策划、个性化健康指导。
8. 打造并运营自主企业:人工智能驱动的初创企业、库存与定价优化、全数字化运营。
9. 推动科学领域的自主探索:药物设计、材料合成、气候建模、新假设测试。
10. 像合作伙伴一样开展创意协作:合著小说、音乐制作、时尚设计、建筑设计。

AI:大约2035年

ChatGPT认为,未来10年AI最可能做到的10类事情
1. 开展科学研究:生成假设、运行模拟、设计并分析实验。
2. 设计先进技术:发现材料、设计生物技术、制作能源系统原型。
3. 模拟类人思维:创建具备记忆、情感和自适应行为的数字人格。
4. 运营自主公司:在极少人工干预下管理研发、财务和物流。
5.执行复杂体力任务:操作工具、组装部件,在现实空间中自适应作业。
6. 全球协调系统:大规模优化物流、能源使用及危机应对。
7. 建模完整生物系统:模拟细胞、基因和生物体,用于研究与治疗。
8. 提供专家级决策:实时给出法律、医疗和商业方面的建议。
9. 塑造公共辩论与政策:主持论坛、提议法律、平衡相互竞争的利益。
10. 构建沉浸式虚拟世界:直接根据文本指令生成交互式 3D 环境。
AI发展趋势:史无前例
* 机器学习是人工智能的一个子集,指机器无需明确编程,就能从数据模式中学习。
注:学术界涵盖由一家或多家机构(包括政府机构)开发的模型。产业 – 学术界合作不包含政府合作关系,仅统计学术机构与企业之间的合作。产业界不包含与非企业实体合作开发的模型。人工智能指数数据提供商 Epoch AI 用 “知名机器学习模型” 指代人工智能 / 机器学习生态系统中影响力特别大的模型。Epoch 维护着一个数据库,包含自 20 世纪 50 年代以来发布的 900 个人工智能模型,依据尖端进展、历史意义或高引用率等标准筛选条目。由于 Epoch 手动整理数据,一些人认为知名的模型可能未被纳入。学术模型数量为零,并非指学术机构在 2023 年未产出知名模型,而是 Epoch AI 尚未认定有知名模型。此外,学术出版物往往需要更长时间获得认可,介绍重要架构、高引用率的论文可能需要数年才会变得知名。由于政府限制,中国相关数据可能存在信息获取方面的限制。来源:内斯特・马斯莱伊等人,《2025 年人工智能指数年度报告》,人工智能指数指导委员会,斯坦福人类 – 人工智能研究所(4/25 发布 )。
机器学习模型,随着数据、计算与资金需求增长,从2015年产业界超越了学术界……
斯坦福 HAI 版 2003-2024 年全球知名机器学习模型行业分布
本图表呈现 2003-2024 年全球 “知名机器学习模型” 的行业( Sector )分布与发展阶段,核心解读如下:
一、阶段划分:学术主导→产业主导
1.学术时代(2003-2014):
以 学术界及少量产业 – 学术合作 ” 模型为主,反映 AI 发展早期学术机构(高校、科研院所 ) 的核心引领作用 —— 依赖基础研究投入,探索机器学习算法(如深度学习雏形 )与应用框架。
模型数量峰值低(年度新增≤20 ),受限于 “算力、数据、商业化路径”,技术突破以论文发表、实验室验证为主。
2.产业时代(2015 – 至今):
产业界模型占绝对主导(2023 年达 60+ ),标志 AI 发展进入企业驱动阶段—— 科技巨头(谷歌、OpenAI 等 )凭借算力集群、海量数据与商业资本,大规模推进模型研发与落地。
增长曲线陡峭,2015 年后产业模型数量持续飙升,反映 “大模型竞赛”“商业化刚需” 对技术迭代的强驱动。
二、行业生态演变
1. 学术影响力式微:
2015 年前,学术界是模型创新主体;2015 年后,产业界凭借资源整合能力(数据、算力、人才 )实现 “弯道超车”,印证 “技术 – 商业闭环” 对 AI 发展的关键作用—— 企业可通过产品化快速回收研发成本,反哺模型迭代。
2. 合作模式分化:
“产业 – 学术合作”(蓝线 )在 2015 年后短暂增长,但规模远低于纯产业模型,反映学术机构与企业的协同困境—— 目标差异(学术追求创新,企业追求落地)、知识产权分配等问题,限制深度合作。
政府、科研集体等其他合作模式(紫、绿线 )占比极低,说明 AI 研发仍以 “企业单打独斗” 或 “学术独立探索” 为主,跨领域协同生态尚未成熟。
三、技术与市场逻辑
1. 资源需求驱动:
机器学习模型对 “数据规模、算力投入、资金消耗” 的需求呈指数级增长(如大模型训练成本超千万美元 ),产业界(企业 )比学术界(依赖科研经费 )更易满足资源需求,自然成为研发主体。
2. 商业化倒逼创新:
企业需通过模型落地(如 ChatGPT、文心一言 )获取市场竞争优势,倒逼技术突破(多模态、推理优化 );而学术界更关注基础理论,导致 “产业应用创新” 与 “学术理论突破” 逐渐分化。
四、趋势与挑战
1. 产业持续主导:只要“数据 + 算力 + 资金” 的资源门槛存在,产业界的研发主导地位将延续,推动 AI 模型向“更通用、更高效、更垂直” 方向进化。
2. 学术角色转型:学术界需从 “模型创新主体” 转向 “基础理论支持者”,聚焦 “长尾问题(如小数据学习、伦理对齐 )” 与 “跨学科突破”,为产业发展提供底层支撑。
3. 协同生态构建:需完善“产业 – 学术 – 政府”协同机制(如联合实验室、知识产权共享 ),平衡创新速度与基础研究深度,避免 “产业过度追求商业价值,学术脱离实际需求” 的割裂。
简言之,图表揭示 AI 发展从 “学术驱动” 到 “产业驱动” 的范式转移,本质是资源配置逻辑与商业需求共同作用的结果。理解这一演变,对把握 AI 研发生态、技术投资方向及产学研协同策略,具核心参考价值。
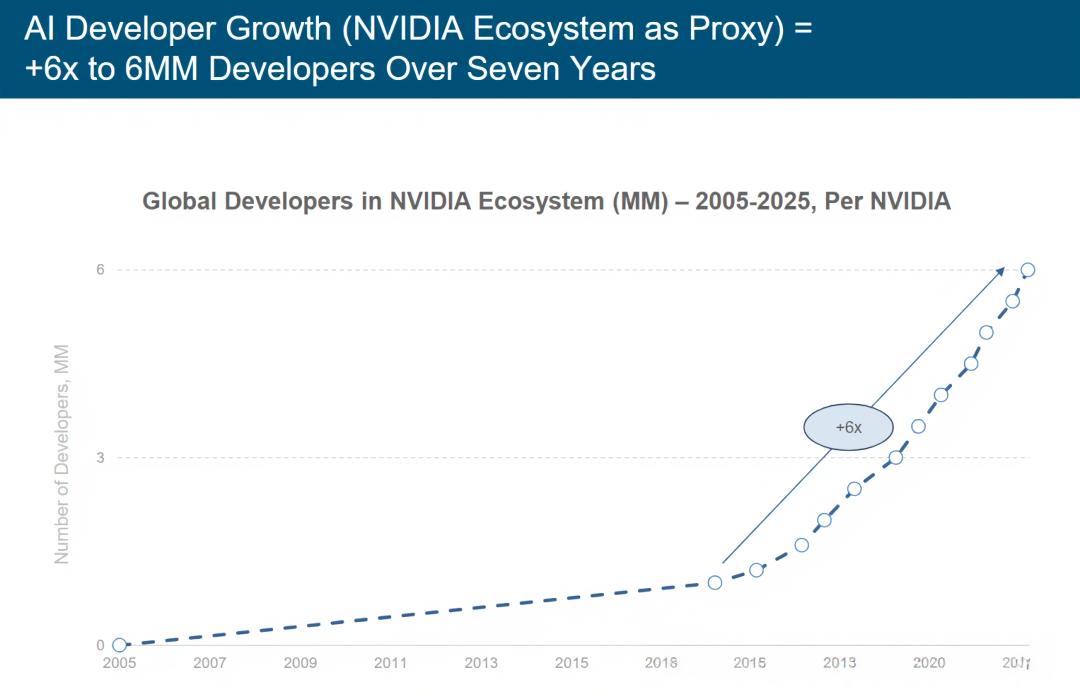
注:依据一篇发布于 8 月 20 日、标题为《200 万注册开发者,无数突破》的博客文章内容,我们假设 2005 年英伟达生态系统中的开发者数量极少。该文章提到:“达到 100 万注册开发者用了 13 年,而达到 200 万用时还不到两年。” 来源:英伟达博客文章、新闻稿及公司概况 。
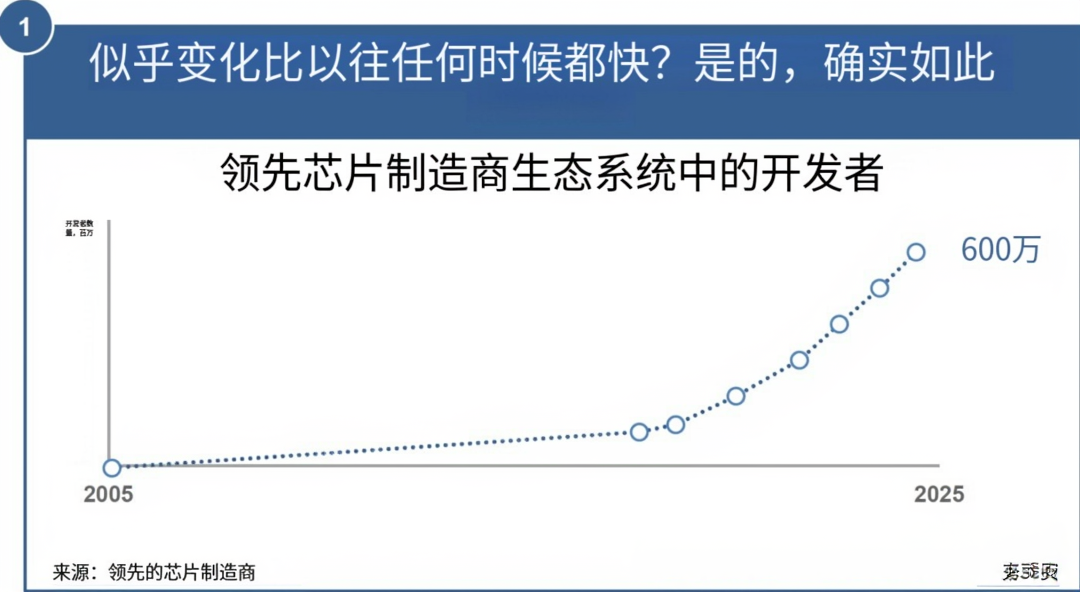
人工智能开发者增长(以英伟达生态系统为代表):七年间增长 6 倍,开发者数量达 600 万
英伟达生态系统全球开发者数量(2005-2025)图表
本图表呈现 2005-2025 年其生态系统内全球开发者数量(单位:百万,MM )的增长趋势,核心解读从产业生态、技术扩散与市场驱动维度展开:
一、增长阶段与速率
1. 早期积累(2005-2018):
开发者数量缓慢爬坡,反映英伟达生态初期以专业技术人群(如 GPU 计算、图形编程开发者 ) 为核心,依赖硬件技术渗透(如 CUDA 架构推广 ),但应用场景较窄(聚焦高性能计算、游戏开发 )。
2. 加速爆发(2018-2025):
曲线斜率陡增,尤其 2020 年后进入 “指数增长区间”,与 AI 技术爆发(大模型、深度学习普及 )强关联 —— 英伟达 GPU 成为 AI 训练 / 推理的核心算力支撑,驱动开发者群体从 “专业小众” 向 “泛 AI 从业者” 扩张(如算法工程师、数据科学家、企业开发者 )。
6倍凸显增长倍率,预计 2025 年达 600 万开发者,印证生态辐射力的量级跨越。
二、生态价值与行业影响
1. 算力生态的 “磁石效应”:
开发者数量飙升,本质是英伟达以GPU 算力为核心,构建 “硬件 – 软件 – 工具链” 协同生态的结果。CUDA 等平台降低 AI 开发门槛,使更多开发者能利用英伟达算力实现创新,反向强化生态粘性(开发者越多→应用越丰富→生态越强大)。
2. AI 产业的 “基础设施红利”:
开发者规模反映 AI 技术的产业化渗透深度—— 从实验室到企业应用,从算法研究到产品落地,英伟达生态成为 AI 创新的 “底层土壤”,驱动行业从 “技术探索” 转向 “规模化应用”。
三、趋势与隐含逻辑
1. 技术扩散的 “临界点”:
2018 年后的加速增长,对应 AI 从 “前沿技术” 进入 “工业化阶段”—— 大模型需求倒逼算力基建普及,开发者数量爆发是技术扩散越过 “临界规模” 的标志,预示生态将进入 “自我强化” 周期(开发者→应用→需求→更多开发者)。
2. 竞争壁垒的构建:
600 万开发者构成强大的生态护城河—— 新进入者需突破 “开发者习惯、工具链兼容性、应用生态丰富度” 的多重壁垒,英伟达借此巩固在 AI 算力与生态协同中的主导地位。
四、关联产业的联动效应
1. 硬件端:开发者增长推动 GPU 需求(训练卡、推理卡 )持续攀升,强化英伟达在算力硬件的市场份额。
2. 应用端:丰富的开发者群体加速 AI 应用落地(如医疗、自动驾驶、工业 ),拓展英伟达生态的行业覆盖边界。
简言之,该图表不仅是英伟达生态 “开发者数量” 的增长记录,更是AI 产业从技术萌芽到规模应用的发展缩影—— 开发者规模的爆发,印证算力基建成为 AI 创新的核心引擎,驱动行业进入 “生态主导、协同创新” 的新阶段。理解这一趋势,对把握 AI 算力竞争、开发者生态布局及技术产业化路径,具关键参考价值。
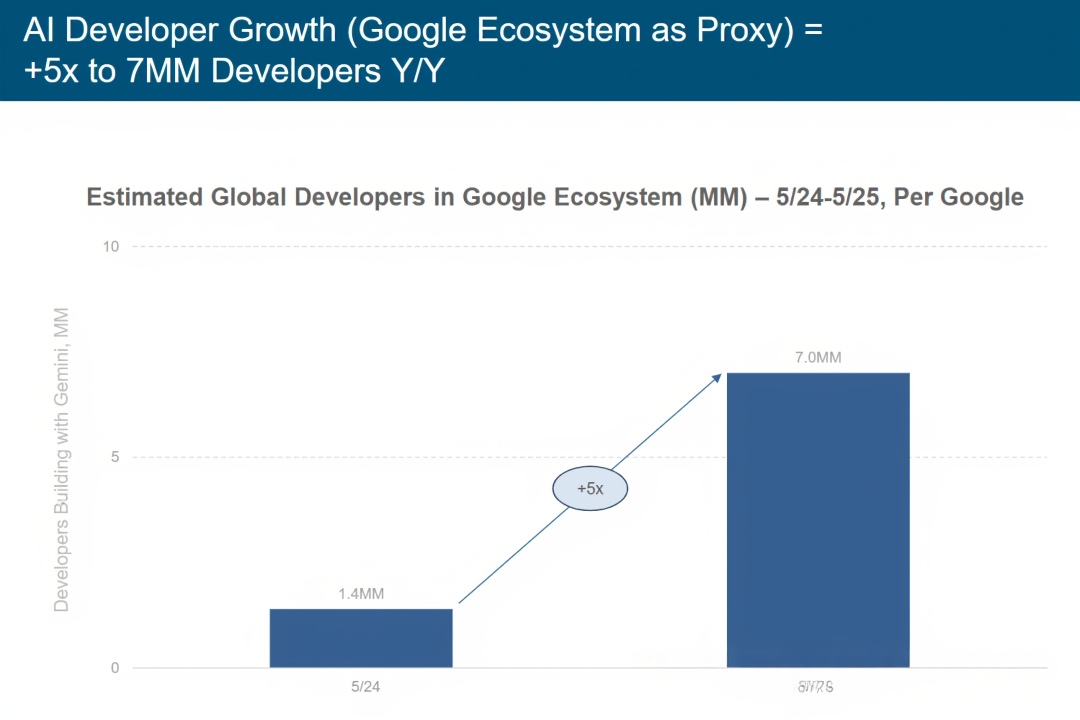
人工智能开发者增长(以谷歌生态系统为代表):年度同比增长 5 倍,开发者数量达 700 万
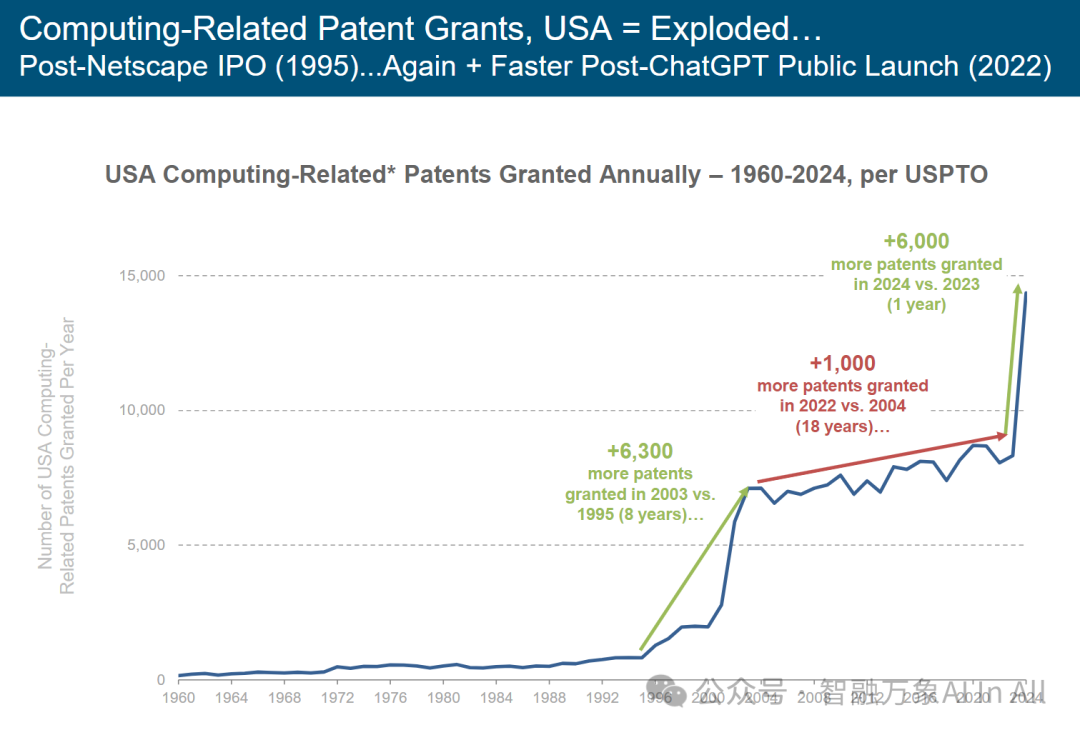
美国与计算相关的专利授权数量:呈爆发式增长……在网景公司首次公开募股(1995 年)之后…… 在 ChatGPT 公开推出(2022 年)之后,再次出现增长且速度更快 。
美国计算相关专利授权量(1960-2024)图表
本图表基于美国专利商标局(USPTO)数据,呈现 1960-2024 年美国计算相关专利年度授权量趋势,从技术创新周期、产业驱动与时代变革维度专业解析:
一、阶段划分与增长特征
长期蛰伏期(1960-1995):专利授权量长期低位徘徊(年授权量<1000 ),反映计算技术早期处于基础理论探索阶段(如计算机体系结构、编程语言雏形 ),创新以学术突破为主,商业化应用尚未大规模触发专利布局。
第一次爆发(1995-2003):授权量飙升(+6300,8 年周期 ),与 “互联网商业化浪潮” 强关联 —— 网景 IPO(1995)开启 “互联网时代”,企业加速布局 “网络技术、软件系统、计算架构” 专利,抢占数字经济先机,驱动专利量指数级增长。
第二次爆发(2022-2024):授权量一年激增 + 6000,与 “生成式 AI(如 ChatGPT )引爆” 直接相关 ——AI 技术突破重构 “计算范式”(从传统编程到智能生成 ),企业 / 科研机构加速布局 “大模型、AI 算法、智能硬件” 专利,争夺下一代计算技术主导权,驱动专利量再次爆发。
二、关键节点的产业逻辑
1995 年拐点(互联网商业化):网景 IPO 标志 “互联网从科研工具转向大众应用”,企业意识到 “计算技术专利” 是商业竞争的核心壁垒,驱动资本与研发资源大规模涌入专利布局,直接催生第一次增长爆发。
2022 年拐点(生成式 AI 革命):ChatGPT 公开推出,使 AI 从 “辅助工具” 升级为 “创新主体”,计算技术的边界从 “程序执行” 拓展到 “智能创造”。企业需通过专利锁定 “AI 驱动的计算创新”(如智能算法、算力调度、多模态交互 ),导致专利申请 / 授权量短期井喷。
三、增长速率的时代对比
1995-2003(8 年 + 6300): 互联网普及驱动 “信息化基建” 专利需求,创新聚焦 “连接与交互”,增长依赖技术落地场景的拓展。
2004-2022(18 年 + 1000): 移动互联网红利见顶,计算技术进入 “存量优化”,创新聚焦 “效率提升”,增长速率自然放缓。
2023-2024(1 年 + 6000): 生成式 AI 重构 “计算价值链条”,创新聚焦 “智能驱动的新可能”,技术突破的 “颠覆性” 直接引发专利布局的 “紧急竞赛”,呈现 “短周期、高增长” 特征。
四、趋势与产业影响
技术范式转移的信号:专利量爆发是“计算技术进入 AI 驱动新阶段”的核心标志,预示行业将从 “传统数字化” 转向 “智能原生” 创新,专利布局方向从 “工具优化” 转为 “智能重构”。
竞争格局的重塑风险:短期专利爆发可能导致 “技术垄断” 与 “创新壁垒”—— 头部企业凭借专利储备占据 AI 计算生态主导权,中小企业面临 “专利追赶” 与 “合规成本” 双重压力。
科研与商业的协同加速:专利增长反映 “学术突破(如 AI 算法 )” 与 “商业落地(如智能应用 )” 的协同效率提升,未来需平衡 “专利保护” 与 “技术开源”,避免创新被过度垄断。
简言之,该图表揭示美国计算技术专利增长的 “双爆发周期” —— 由互联网与 AI 两次技术革命驱动,本质是 “计算范式变革” 引发的产业专利布局竞赛。理解这一规律,对预判技术创新方向、企业专利战略及政策引导逻辑,具核心参考价值。
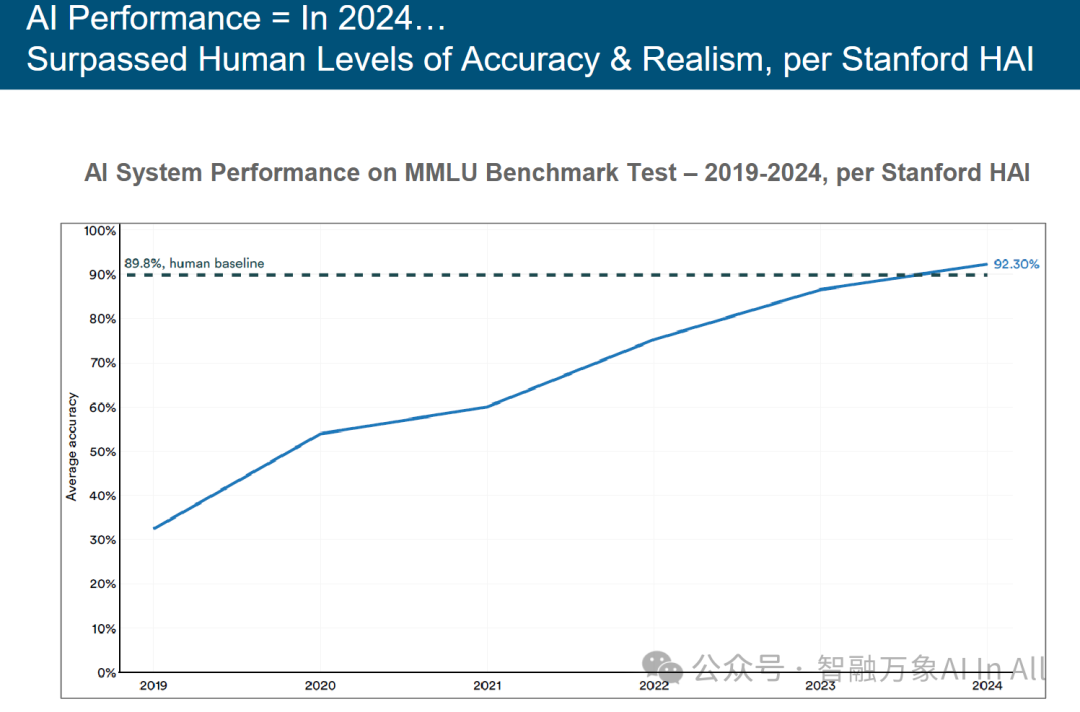
注:MMLU(大规模多任务语言理解)基准测试用于评估语言模型在 57 个学术和专业学科(如数学、法律、医学和历史)上的表现。它同时衡量事实回忆和推理能力,是评估大语言模型中常识和问题解决能力的一项标准。89.8% 是公认的人类表现基准。以上统计数据展示了每一日历年度中表现最佳的人工智能模型的平均准确率。来源:Papers With Code,数据源自内斯特・马斯莱伊等人所著《2025 年人工智能指数年度报告》,由人工智能指数指导委员会、斯坦福人类与人工智能研究所发布(4/25 发布 )。
斯坦福人类与人工智能研究所称,2024年的表现,超越人类水平的准确率与真实感
斯坦福 HAI 版 2019-2024 年 AI 系统 MMLU 基准测试表现
本图表呈现 AI 系统在 MMLU(大规模多任务语言理解)基准测试中的性能演进(2019-2024),从技术突破、能力边界与人类对比维度专业解析:
一、核心指标与基线
1. 人类基线(Human Baseline):89.8% 的准确率,代表经统计验证的人类在 57 个学术 / 专业领域(数学、法律等 )的平均表现,是衡量 AI 能力的 “参照系”。
2. AI 准确率(Average Accuracy):曲线反映顶尖 AI 模型在 MMLU 测试中的平均准确率,衡量模型 “跨领域知识掌握、推理能力” 的综合水平。
二、阶段增长与技术逻辑
1. 突破期(2019-2021):AI 准确率从 30%+ 快速攀升至 60%,对应大模型技术的初步成熟——Transformer 架构普及、预训练数据规模扩张,使模型能学习更广泛的知识与推理模式,突破早期 “窄领域应用” 局限。
2. 逼近人类期(2021-2023):曲线加速逼近 89.8% 基线,反映模型优化与工程化突破—— 通过强化学习、多模态融合、思维链(Chain of Thought )等技术,提升 “知识关联、复杂推理” 能力,缩小与人类的差距。
3. 超越人类期(2023-2024):准确率突破 92.30%,标志 AI 在 MMLU 测试中全面超越人类平均水平。这一跨越源于 “超大模型(如 GPT-4、Gemini )+ 精细化调优”,模型可更高效整合跨领域知识,执行复杂逻辑推理,甚至在部分学科表现优于人类专家。
三、能力边界的本质变化
1. 知识覆盖维度:MMLU 涵盖 57 个学科,AI 从 “单一领域专精” 转向 “跨领域通才”,证明模型能处理多源异构知识(如同时理解法律条文与医学案例 ),知识整合能力超越人类个体的学习极限。
2. 推理深度维度:测试要求 “事实回忆 + 逻辑推理”,AI 突破 “记忆复述” 阶段,可执行多步骤、反事实推理(如模拟历史事件的不同发展路径 ),推理复杂度逼近甚至超越人类。
四、产业与社会影响
1. 技术标杆意义:超越人类基线,标志 AI 从 “辅助工具” 进化为 “知识推理主体”,为智能决策(如医疗诊断、法律咨询 ) 提供更可靠的技术支撑,推动行业从 “人力依赖” 转向 “AI 协同”。
2. 伦理与应用风险:AI “知识推理超人类” 可能引发 **“决策信任危机”** —— 若 AI 结论与人类经验冲突,如何验证?需建立 “AI 决策可解释性” 框架,平衡技术效率与结果可信度。
3. 教育与学习变革:MMLU 反映 AI 的 “知识掌握度”,预示教育将从 “知识传授” 转向 “思维协同”—— 人类需培养 “与 AI 互补的能力”(如创意、情感理解 ),重构学习与工作模式。
简言之,该图表揭示 AI 在 “跨领域知识推理” 上的里程碑突破:2024 年以 92.30% 准确率超越人类平均水平,标志通用人工智能(AGI )能力边界的实质性拓展。理解这一趋势,对把握 AI 技术落地、伦理治理及人类 – AI 协作模式,具核心参考价值。
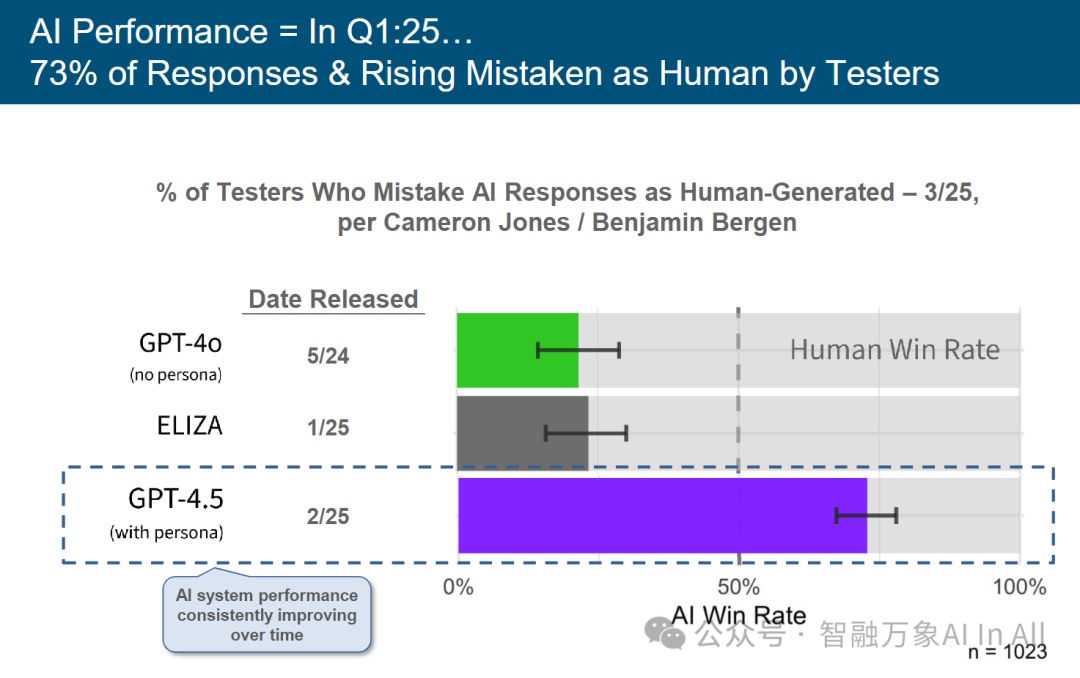
到2025年第一季度,AI的表现,73% 的回复(占比还在上升)被测试人员误认为是人类回复。
本图表由 Cameron Jones / Benjamin Bergen 制作,呈现不同 AI 系统(GPT-4o、ELIZA、GPT-4.5 )在 “人类 – AI 回复辨别测试” 中的表现(AI Win Rate:测试者误判 AI 回复为人类生成的比例 ),从模型拟人性、技术演进与用户认知维度专业解析:
GPT-4o(无角色设定,5/24 发布 ):
绿色柱体显示 AI Win Rate 处于中低区间,反映模型在 “无特定角色约束” 下,输出风格可能偏向标准化、功能性,与人类真实对话的 “个性化、随机性” 存在差异,较易被测试者识别。
ELIZA(1/25 发布 ):
灰色柱体表现与 GPT-4o 接近,说明该模型在 “拟人性优化” 上无显著突破,可能受限于训练数据、架构设计,仍未有效模拟人类对话的复杂特征。
GPT-4.5(带角色设定,2/25 发布 ):
紫色柱体显著高于前两者,且逼近 Human Win Rate 虚线,印证“角色设定(Persona )” 对拟人性的关键提升—— 通过赋予模型特定身份、性格与语言风格,使其输出更贴近人类真实对话(如情感化表达、个性化视角 ),大幅降低被识别为 AI 的概率。
从 “通用输出” 到 “角色赋能”:
GPT-4.5 的突破,反映AI 研发从 “追求绝对准确率” 转向 “模拟人类交互本质”—— 角色设定使模型输出具备情境化、人格化特征,弥补传统大模型 “冰冷、机械” 的缺陷,更契合人类对 “自然对话” 的认知。
拟人性的商业与社会价值:
高 AI Win Rate 意味着模型可更自然地融入客服、教育、陪伴等场景,降低用户对 “AI 身份” 的抵触,提升技术落地的接受度与沉浸感。
“AI – 人类” 边界模糊化:
GPT-4.5 的表现预示 “AI 拟人性” 已达新高度,用户将更难区分 “机器回复” 与 “人类表达”,需建立“AI 内容标识”等伦理规范,避免信息误导(如虚假对话、深度伪造 )。
技术迭代的 “角色依赖”:
角色设定成为提升拟人性的关键路径,但也可能引发 “过度人格化” 风险 —— 若模型被赋予极端 / 误导性角色,可能强化偏见、操纵认知,需平衡 “拟人性” 与 “价值观对齐”。
简言之,图表揭示 AI 拟人性的 “角色驱动突破” —— 通过人格化设定,GPT-4.5 大幅提升 “以假乱真” 能力,标志 AI 交互从 “工具属性” 转向 “类人体验”。理解这一趋势,对把握 AI 产品设计(如对话系统 )、伦理治理及用户体验优化,具核心参考价值。
模拟人类行为、愈发逼真的对话
图灵测试背景(What Was Tested)
图灵测试由艾伦・图灵在 1950 年提出 ,用于评估机器展现出与人类难以区分的智能行为的能力 。测试中,人类评估者需判断对话回应来自人类还是机器,若无法可靠区分,机器即通过测试 。此处参与者要判断 Witness A 和 Witness B,谁是 AI 系统、谁是人类。
测试对话与结果(Results)
对话内容:左右两侧分别是 Witness A 和 Witness B 与测试者的对话,围绕 “是否喜欢做心理研究、简易纸杯蛋糕食谱、最喜欢的奇特动物” 等日常且带个人化的话题展开,模拟真实人际交流场景。
测试结果:2025 年 3 月用 GPT-4.5 开展测试,参与者误判左侧图像(Witness A)为人类的确定性达 87% ,认为 “A 有人类气质,B 有人类模仿气质” ,但实际 A 是 AI 生成,B 是人类 ,说明 GPT-4.5 生成的对话,在模拟人类行为、混淆人类判断上已达到较高水平,体现 AI 对话逼真度的显著提升。
该图通过图灵测试实例,直观呈现 GPT-4.5 在模拟人类行为对话上的出色表现,AI 生成内容已能高度模仿人类交流风格,成功 “欺骗” 人类评估者,反映 AI 在对话拟人性发展上的重要进展 。

愈发逼真的图像生成
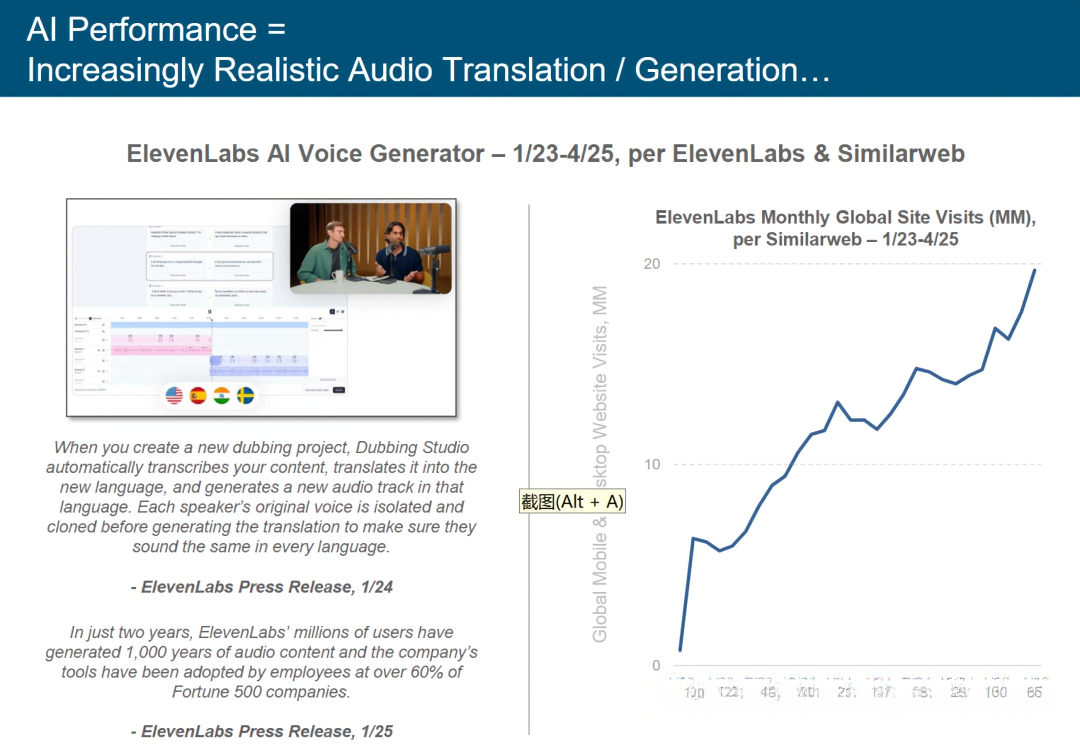
人工智能性能表现 = 愈发逼真的音频翻译 / 生成……
人工智能性能:愈发逼真的音频翻译与生成 ——ElevenLabs 案例解析
本图以 ElevenLabs AI 语音生成器为研究对象,结合其 2023 年 1 月 – 2025 年 4 月数据(源自 ElevenLabs 官方与 Similarweb ),从技术能力、市场接受度、行业渗透维度专业解读:
一、技术能力呈现:配音工作室的流程革新
ElevenLabs 的配音工作室(Dubbing Studio )实现“转录 – 翻译 – 语音克隆 – 音轨生成”全流程自动化:
1. 转录与翻译:创建配音项目时,系统自动识别内容文本、完成多语言转换,突破传统音频本地化 “人工听写 + 翻译” 的低效模式。
2. 语音克隆:分离并克隆说话人原始声纹,确保多语言转换后 “音色一致性”—— 这是实现 “逼真音频生成” 的核心技术(解决跨语言配音 “声线割裂感” 难题 ),使 AI 生成音频无限贴近人类真实发声。
二、市场接受度:全球站点访问量的爆发增长
右侧折线图(Similarweb 数据 )呈现 ElevenLabs 月度全球站点访问量(单位:百万,MM )的指数级攀升:
1. 增长周期:2023 年 1 月 – 2025 年 4 月,访问量从接近 0 快速突破 2000 万,反映市场对 “AI 语音生成” 需求的爆发式增长。
2. 驱动逻辑:音频翻译 / 生成的 “高拟人性”,契合内容全球化(如播客、影视本地化 ) 与个性化交互(如虚拟人、智能客服 ) 需求,企业与个人用户通过访问平台,验证并应用该技术。
三、行业渗透:从用户规模到企业级采纳
ElevenLabs 的用户与客户数据,印证技术的产业影响力:
1. 用户创作力:两年内,数百万用户生成 “1000 年时长音频内容”—— 说明 AI 语音工具降低创作门槛,激发 “大规模音频生产”(如多语言播客、有声书 )。2. 企业级采纳:超 60%《财富》500 强企业员工使用其工具,反映 AI 语音生成从 “消费级尝鲜” 进入 “企业级生产力工具” 阶段,成为全球化业务(如跨语言会议、品牌内容本地化 ) 的关键支撑。
四、技术与产业的协同启示
1. 拟人性是核心竞争力:音频生成的 “高逼真度”(声纹克隆、自然语气 ),是 ElevenLabs 突破市场的关键 ——AI 性能已从 “功能实现” 升级为 “体验还原”,拟人性成为技术落地的核心指标。
2. 需求驱动技术迭代:访问量爆发与企业采纳,反向推动技术优化(如支持更多语言、更复杂声线克隆 ),形成 “需求 – 技术 – 需求” 的正向循环。
3. 产业边界的拓展:AI 语音生成不再局限于 “娱乐内容”,已渗透至企业沟通、品牌传播、教育医疗(如多语言医疗问诊、智能教学 )等领域,重构 “音频内容生产与交互” 的行业生态。
简言之,ElevenLabs 的案例揭示:AI 音频翻译 / 生成的 “高拟人性”,正在驱动技术采纳从 “小众尝鲜” 转向 “大规模应用” ,并通过重塑音频生产流程,深刻影响内容全球化与企业数字化转型。理解这一趋势,对布局 “语音 AI” 赛道、优化跨语言内容策略,具核心参考价值。

人工智能性能表现:逐步发展为主流的逼真音频翻译 / 生成
2025 年第一季度,Spotify(声田)月活跃用户达 6.78 亿,订阅用户为 2.68 亿;平台承载超 1 亿首曲目、约 700 万档播客节目及约 100 万名创意艺人,年营收折合年化达 168 亿欧元 。
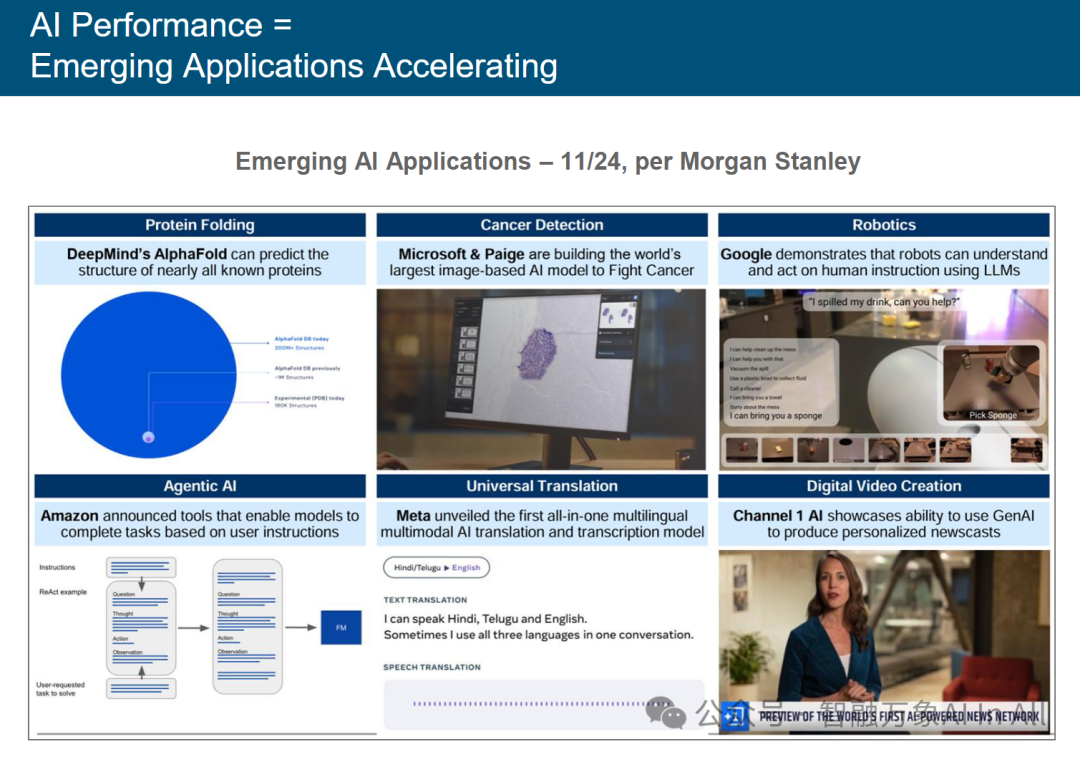
人工智能性能表现 = 新兴应用加速涌现
本图呈现六大 AI 前沿应用场景,从技术突破、行业价值、生态构建维度专业解读:
简言之,本图展现 AI 新兴应用的“广度突破与深度渗透”—— 既覆盖前沿科学(蛋白质折叠 ),又下沉行业场景(癌症检测、机器人 ),标志 AI 从 “技术概念” 全面进入 “产业实用化” 阶段。理解这些应用,对布局 AI 赛道、挖掘行业机遇、应对伦理风险,具核心参考价值。

AI:好处和风险
人工智能广受热议的益处与风险 —— 许多人都极为关注 —— 引发了合理的兴奋与不安情绪,而变化的迅猛速度、日益激烈的全球竞争以及(各方的)武力恫吓所带来的不确定性,进一步加剧了这种情绪。
斯图尔特・罗素(Stuart Russell)和彼得・诺维格(Peter Norvig)两位专家在其长达 1116 页的经典著作《人工智能:一种现代方法》(2020 年第四版,链接见此 )中深入探讨了这些话题,他们的观点至今仍站得住脚。
以下是要点提炼:
关于益处:简而言之,我们整个文明都是人类智慧的产物。倘若我们能够运用到强大得多的机器智能,(我们的)抱负上限便会大幅提升。人工智能和机器人技术有望将人类从琐碎重复的工作中解放出来,并大幅增加商品和服务的产出,这可能会预示着一个和平富饶时代的到来。加速科学研究的能力,可能会带来疾病的治愈方法,以及应对气候变化和资源短缺的解决方案。正如谷歌深度思维(Google DeepMind)首席执行官戴密斯・哈萨比斯(Demis Hassabis)所言:“先解决人工智能问题,然后用人工智能解决其他所有问题。”
然而,远在我们有机会 “解决人工智能问题” 之前,我们就会因人工智能被滥用(无论是无意还是有意为之)而面临风险。其中一些风险已然显现,而基于当前趋势,其他一些风险似乎也有可能出现,包括致命性自主武器…… 监控与 persuasion(可译为 “诱导、劝服” ,结合语境指利用 AI 进行的宣传、诱导等行为 )…… 有偏见的决策制定…… 对就业的影响…… 安全关键型应用…… 网络安全……
来源:斯图尔特・罗素和彼得・诺维格,《人工智能:一种现代方法》

成功创造出人工智能可能会是我们人类文明历史上最为重大的事件。但它也可能会是(人类文明的)最后一个重大事件 —— 除非我们学会如何规避相关风险。
—— 斯蒂芬・霍金,理论物理学家 / 宇宙学家(1942 – 2018)